WebLogic Major Upgrade Without Downtime
A trip down memory lane… A long time ago, in 2015, we were running an Oracle WebLogic 11G cluster, which needed to be upgraded to 12C. However, Oracle did only support rolling upgrades for minor versions, not for major versions…
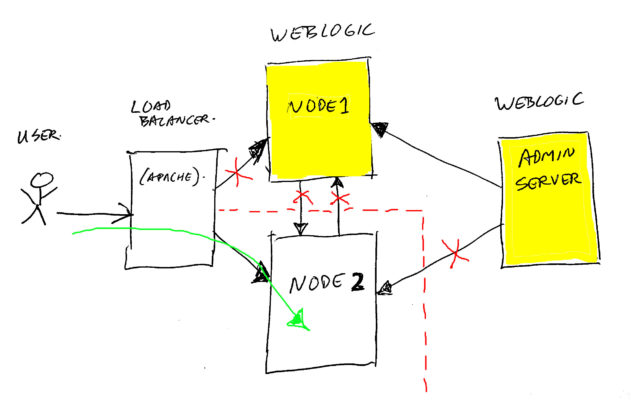
In the image above, you see a simplified layout of our cluster (there were more servers and instances in the real setup).
Traffic comes in from the left, via a load-balancer (and some apache’s). It was spread across the managed servers (WebLogic Nodes). And these managed servers were managed by the WebLogic Admin Server on the right.
An upgrade from 11G to 12C would not be possible without downtime, but we did not like that option for our busy production web-site. So I came up with a trick… Our nodes (I think we had 4 of them per cluster) were not all needed during the not so busy hours of the day. So we simply made half the cluster serve the website, and upgraded the other half.
WebLogic admin server and nodes keep talking to each other to communicate their state, and handle deployment upgrades. To prevent the running nodes from getting confused by the new version install network chatter, we isolated the running nodes like this:
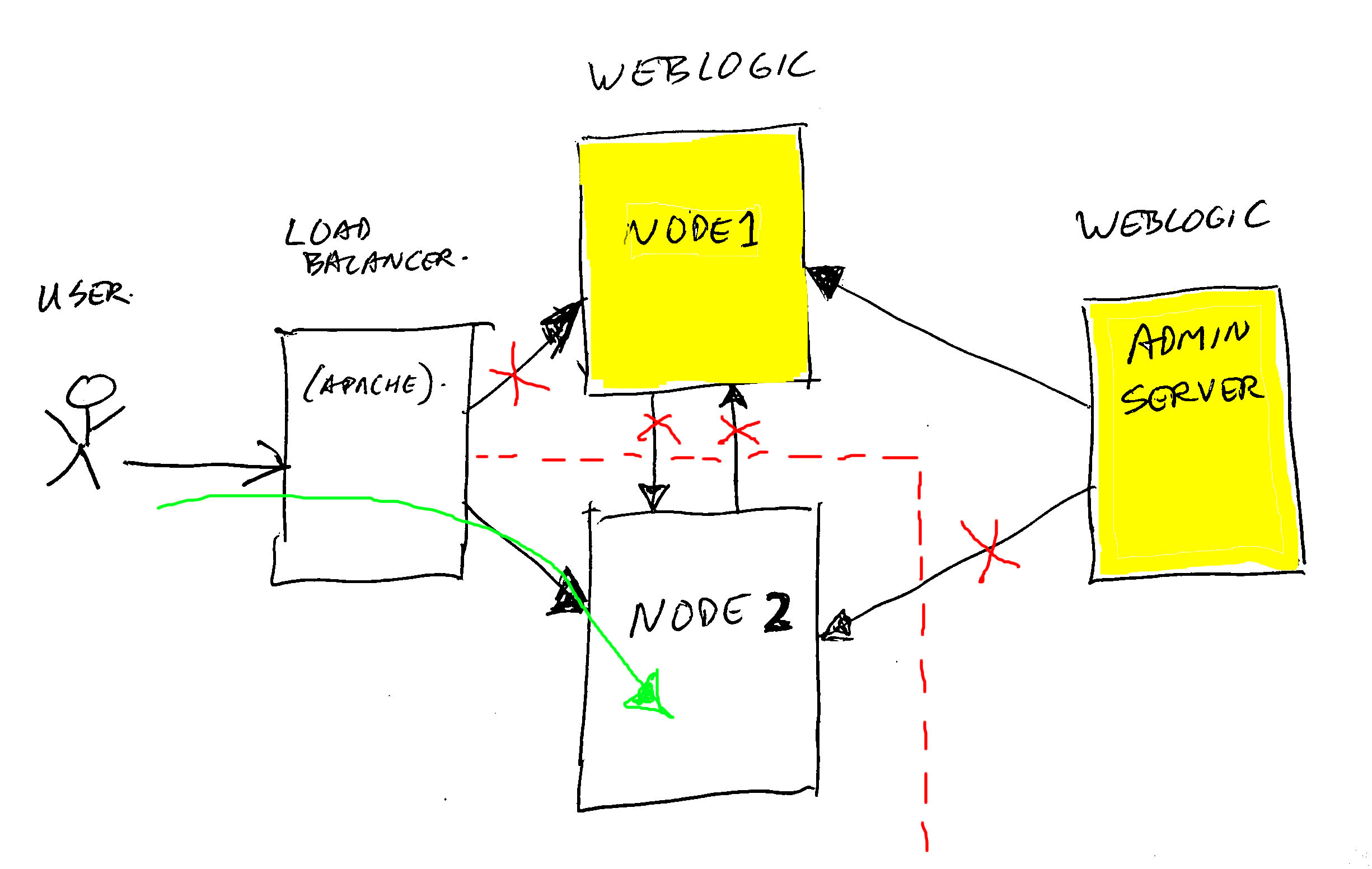
On node 2, we executed something similar to the following ip-tables (firewall) commands, to isolate it from node 1 and from the admin server:
iptables -A INPUT -s <admin-ip> -j REJECT -reject-with-icmp-port-unreachable
iptables -A OUTPUT -m state --state NEW -d <admin-ip> -j DROP
iptables -A INPUT -s <node1-ip> -j REJECT -reject-with-icmp-port-unreachable
iptables -A OUTPUT -m state --state NEW -d <node1-ip> -j DROPCode language: HTML, XML (xml)And also we updated the load-balancer (apaches) to only route traffic to node 2.
This way, the customer traffic was handled via the green route by node 2. And node 2 was blind to the yellow node 1 and admin server. But… as long as your node is running, it will keep working, so no problem.
Now we could delete all traces of WebLogic 11G completely from node 1 and from the admin server. And after that, we ran our puppet installation scripts to re-install them automatically, using the new 12C version.
After installing 12C, we could first test via an internal connection if the new server worked properly, and the site would be OK. Of course this also was tested on our non-production servers before we started the upgrade.
After seeing that all was OK, we switched traffic to node 1, and deleted node 2, removed the iptables blocking rules (use -D instead of -A in the commands), and re-installed node 2 with 12C using puppet. After double checking it was fine, we enabled the load-balancer again to split the load across all nodes. And all was done!
Conclusion:
By thinking a bit out-of-the-box, we were able to do a smooth upgrade (during early office hours), in a real short time (due to the use of puppet for installation). Things which seem impossible do not need to be impossible 😉
But, as said, this was a trip down memory lane…
We did use WebLogic and WebSphere in the past, we did not like both of them, as they always gave deployment issues, and needed lots of attention and occasional unwanted restarts when something got stuck.
Gradually, we moved to using Tomcat, which proved to be faster, and much more stable, and used simple software deploys. And of course Tomcat is free, instead of the license costs you have for Oracle and IBM.
And later on, we started moving everything to cloud / Docker / Kubernetes, using smaller containers with spring-boot/tomcat/netty or other small app-servers in them. Much much more flexible!
Thijs, 22/11/2020.
Note: we were using the WebLogic knowledge from Qualogy at that time, and they posted this same data on their own site also. See:
https://www.qualogy.com/techblog/java-web/how-to-rolling-upgrade-weblogic-11g-to-12c