Micro-services Architecture with Oauth2 and JWT – Part 6 Oauth2 and Web
The last number of years I have been working in the area of migrating from legacy monolith (web) applications to a (micro) service oriented architecture (in my role of Java / DevOps / Infrastructure engineer). As this is too big of a subject to put in a single blog post, I will split this in 6 parts; (1) Overview, (2) Gateway, (3) Identity Provider, (4) Oauth2/Scopes, (5) Migrating from Legacy, (6) Oauth2 and Web.
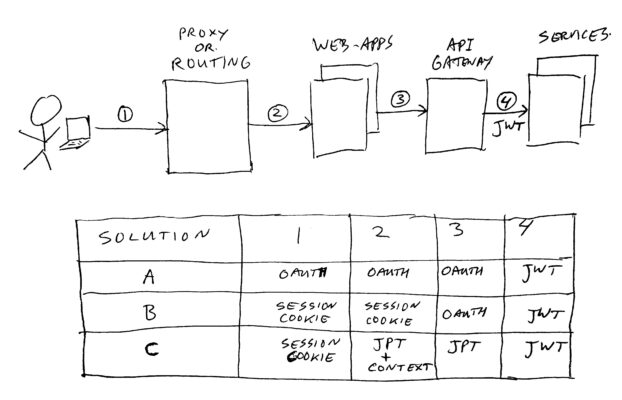
Oauth2 and Web: To-Do or not To-Do – That’s the Question…
The image above shows 3 solutions, which will be discussed in this post.
Introduction
In this last part, I will cover Oauth2 and web with respect to using the micro services landscape.
When going to a micro services architecture, you need some way of securing your services from unwanted outside access. We chose for Oauth 2.0, which is a commonly used standard.
We use this both for third parties using our services, and for our mobile apps, and also up til now for our website.
First Web Iteration (solution A)
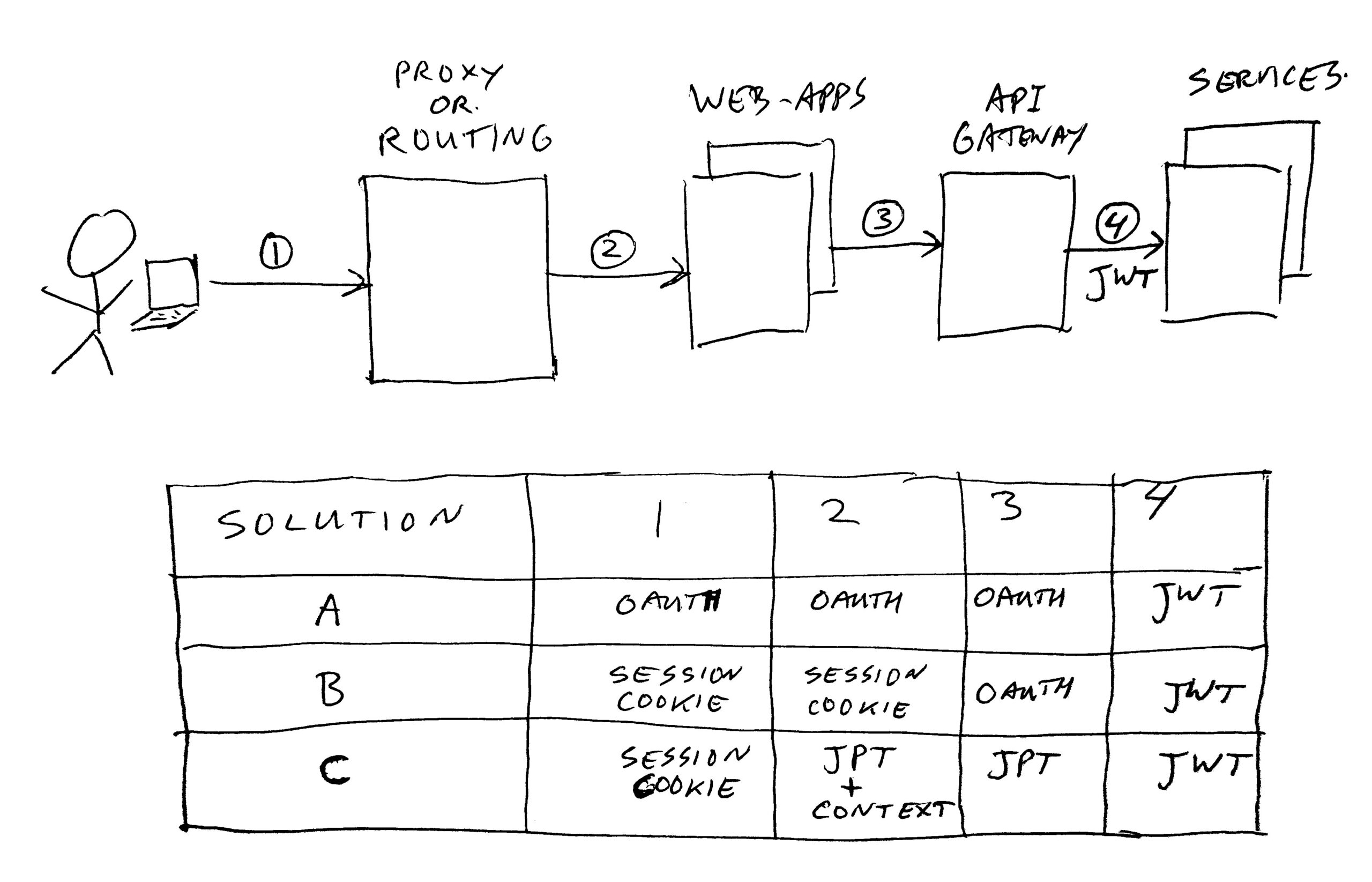
For web, we initially chose to use Oauth2. We have been running with this setup for a couple of years now. In this version, we do send token cookies to the end-user in his/her browser, and use these when entering the web-applications. Our users have 3 states;
- anonymous; new visitors, for which we do not remember anything yet. These can query public data.
- returning; users which come back to our site, for which we do have to remember something. For example a favorite recipe, or some stuff on a shopping-list.
- logged-on; a registered user, who is actively logged on. These users can query private personal data.
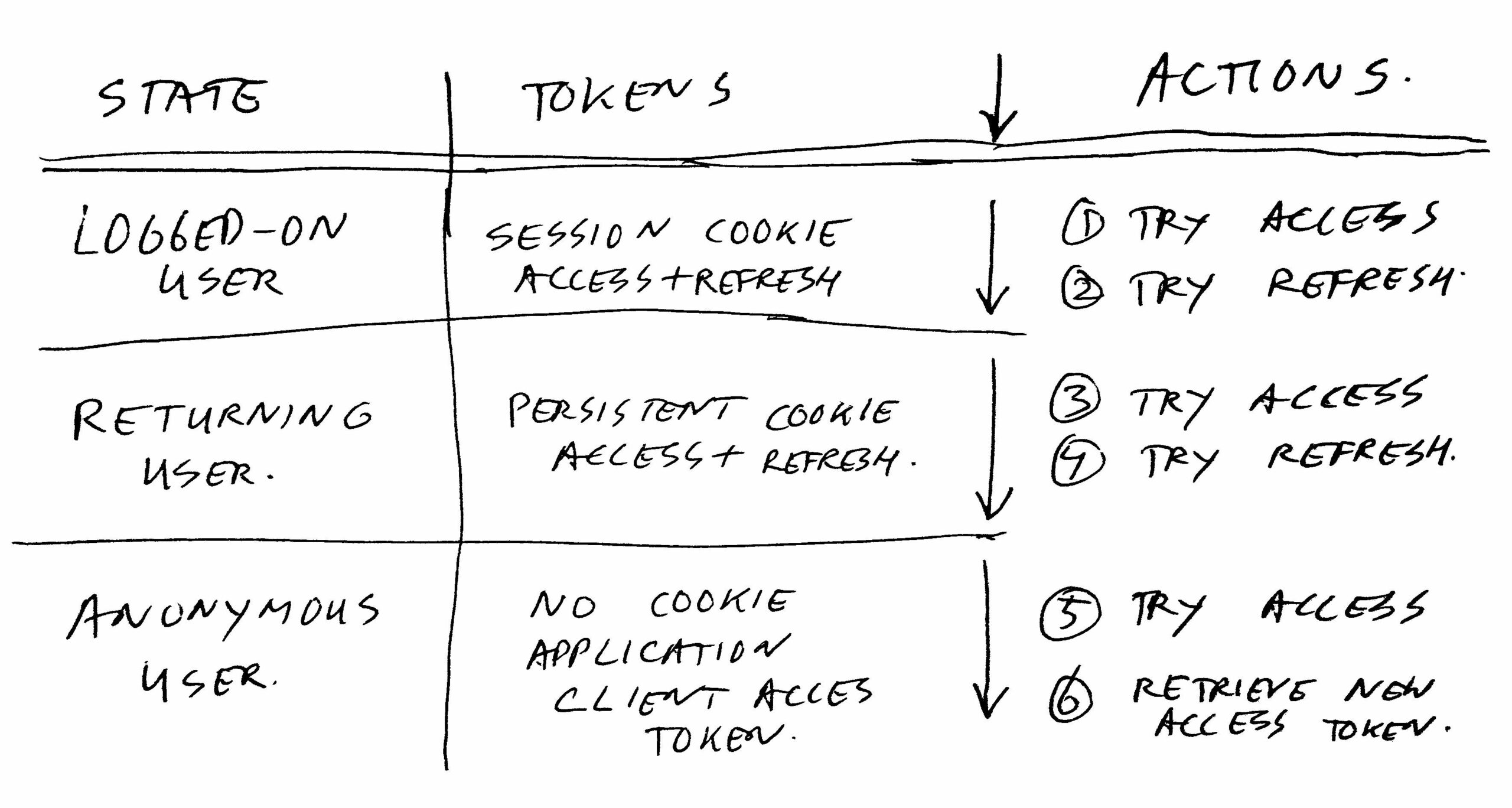
Access tokens are valid for 2 hours. The refresh token for logged-on state is valid for max 4 hours, and won’t be extended. Refresh token for returning state user is valid for one week, and is extended on each refresh. But… tokens can also be deleted or invalidated due to other reasons. For example if using too many tokens per user, or when a user changes his/her password. Or simply by hitting log out.
So here some points of what we need/do for this:
- We put access and refresh tokens in cookies for states logged-on and returning.
- We cache a client (application) token in the web-apps for state anonymous.
- We have complex libraries to choose which token to use:
- This checks for logged-on, then returning, and falls back to the anonymous client token.
- For each of them, it tries to use the access token, and if the service calls fails, refreshes it and tries again.
- If refresh fails, it falls back to the next token in line, until you end up at the anonymous client token.
- If one of the steps succeed, but a new token was generated, the user must receive a new set of cookies with the new tokens.
- If you end up in a level which is too “low” for the page you are visiting, the web-app needs to send you to the login page.
- This has been implemented in old monoliths and new architecture web-app’s.
- It is complex, and causes many delays due to retries/refreshes (worst case; 6 steps before your service call works).
From above bullets, you probably already feel that I’m not too fond of this implementation… It does work, but has its costs. And many developers don’t understand what is going on exactly. It’s also difficult to trouble shoot.
Next Web Version (solution C)
(Yes; skipping solution B, it will follow later – we do not use B)
So I decided that our first web setup was not really workable anymore, and came up with a new solution. It throws Oauth2 overboard for web, for the most part. But we keep using the micro services landscape, and the services do not see the difference between the Oauth2 callers, and the new web callers. This last part is quite important, as we have many services, and we did not want to let them use some new authentication mechanism. The services still use JWT (Oauth was handled by our Gateway/IDP, and access tokens are exchanged by the gateway for JWT before going to the services).
In the new setup, the web-apps pass on something which looks like a JWT (has the same attributes – we call it a JPT) to the Gateway, and the Gateway transforms it back to a JWT to call the services.
So how do the web-apps get the JPT? We have made a central proxy, through which ALL requests have to go, before ending up in the web-apps. The proxy handles the user context by setting a session and returning customer cookie in the user’s browser (containing random session ID values). It then uses the cookie values to look up the user context in a database, and part of this context is the JPT.
Let’s throw all of this in an image to make it a bit more clear:
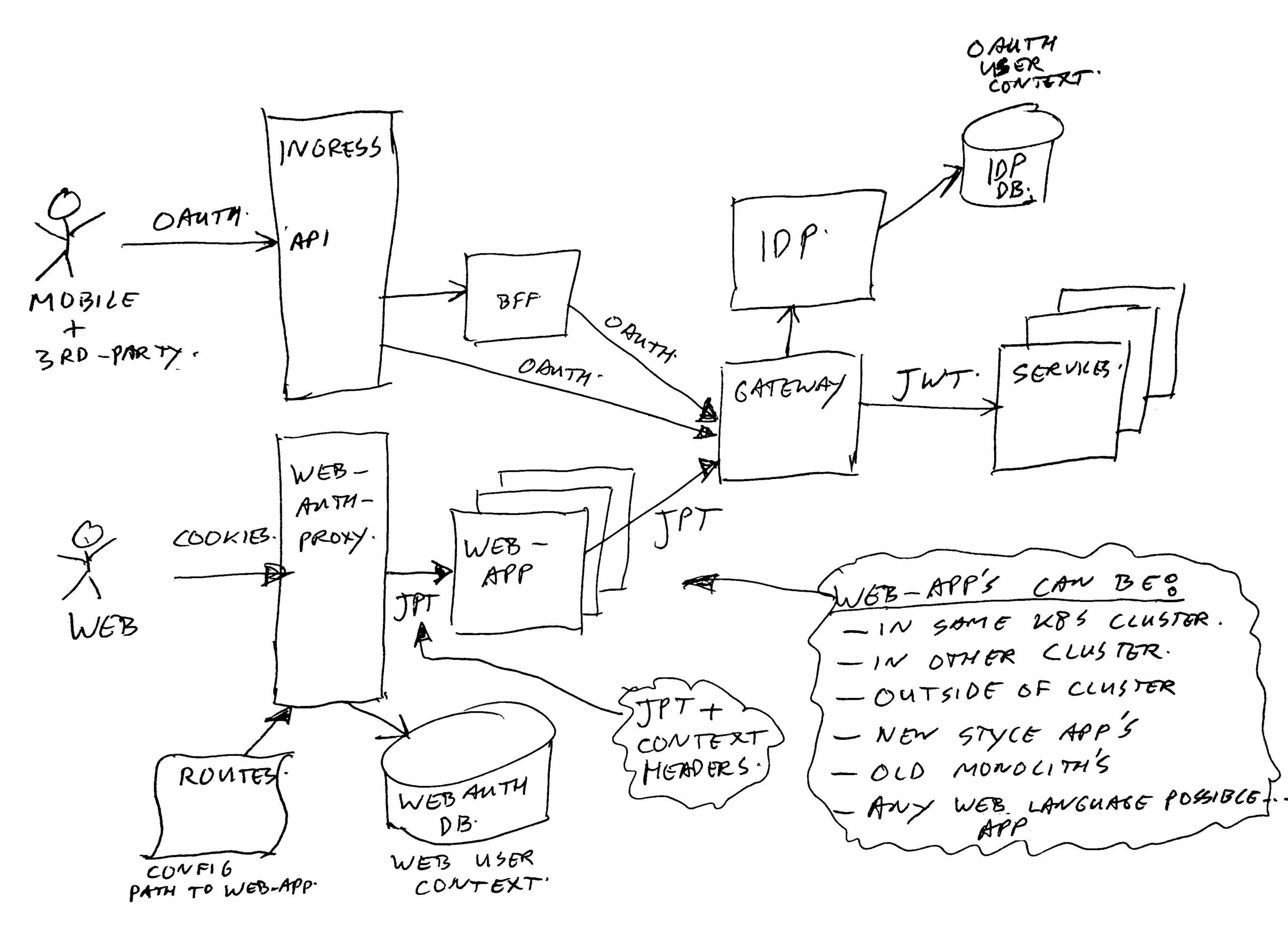
The top-left part is the mobile app, and 3rd party Oauth2 entrance. And below it, you see the new proxy for web traffic. We run in Kubernetes, which normally uses ingress (Nginx) for mapping inbound traffic to running applications. The new proxy takes over that role for web traffic.
So in short, the central proxy does / handles:
- Cookie management.
- Look up user context.
- Pass on the user-context to the web-app’s (we use request headers for that).
- Handle user-context updates passed back from web-app’s to the proxy (via response headers).
- Use JWT in instead of Oauth2 to talk to services, via same gateway as Oauth2 traffic. We gave the token a new name (JPT = Json Proxy Token), and a different signature to force web-app’s to go via the central Gateway to the services.
- The proxy does the routing from each context root pattern to the proper web-app.
This all looks nice and simple. The web-app’s do not have to do token magic anymore, no 6 times retry or refresh. They receive the user context and JPT, and can pass the JPT on to Gateway when calling services without having to worry about validity.
We still use the IDP to create the JWT (and JPT), so we have only place where we configure what a token may do (which scopes it has). And the IDP is the only one who can sign the JWT/JPT, to keep this secure.
Note: although it looks simple, there is an amazing set of complex rules in the new proxy, to keep an eye on the user context, get fresh user information in there (by talking to the user database and IDP, not just the session storage). And it determines when a user should be logged out automatically. It keeps an eye on security, auditing, and logging. And it needs to be really fast in handling lots of requests! Our website is not that small.
So yes, the proxy is complex. But… all complexity is centralized, and removed form all web-app’s. So web-apps will become much simpler, and this way the web-app builders can also choose from any language to build the app in. As they do not need to include our Oauth2 library framework anymore.
Note: we are currently building and finishing off this new architecture (I’m writing this end of 2020). And hope to get it live in Q1 of 2021. So it will have to prove itself. But I’m confident this will work fine, and makes everything infinitely easier.
Another Web Option (solution B)
As alternative to the above two described solutions (A and C), you can also go for using an old fashioned web-session with session cookies between the user, and the web-app’s. And then let the web-app’s use an Oauth2 application / client token to talk to the services.
This way you have only one type of token, which can be re-used for all users, and will save a lot of unnecessary refreshes.
We did not go for this option, as our services often do expect a user specific access token context in their JWT. This would need quite some rewrites, and a change in trust relation between web and services.
Just as in solution C, in this solution B you also need some sort of shared session storage, to give all web-app’s knowledge about the user in context. To be able to pass on user specific attributes to the services.
Closing Thoughts
Oauth 2.0. Good or bad?
For machine-2-machine communications (for example mobile app’s or batch jobs), or from external parties to your micro services. I would say yes, that’s a good plan. It’s a clear and proven standard.
The 3-Legged Oauth login is really nice to connect 3rd party sites to your user accounts. You can let the user choose to authenticate him/her-self to the other site using the same set of credentials. And the external site will never need to know the user’s credentials to accomplish this. (As reminder, the 3-Legged login works by redirecting the user from a 3rd party site to our site, log in there, and then redirect back. And the 3rd party site then can get an access and refresh token for the user, to execute service calls on behalf of that user).
When using it from an internal application, to your own micro services, using some highly trusted application / client token setups, not too fine grained access control (solution B). I would also say yes if it’s really needed. If you have a different way of securing connections from your web engines to your services (separate dedicated networks with firewalls?), I would go for that option, and make sure the services just fully trust the internal applications. No need for additional complexity.
When you try to use it as we did (solution A), having multiple end-user states, each having it’s own clients and tokens, and passing that all from the end-user (cookies) to the services… I would say NO. Don’t go that route. way too complex, and causing lot’s of delays.
If you have only two states, anonymous, and logged on, so just one access and refresh token per user, you might consider using it that way (solution A). But still, I do not like the fact that all your web-app’s need to refresh and retry when stuff expires.
For distributed web-app’s using micro services, I would opt for having a central session storage, and using a central proxy to handle cookie to session translation and the other way around (solution C). Much cleaner and simpler.
Solution C also allows you to create a real “session” with custom attributes for the user session if you want to. For some reason, some people on the project do not want a “session”, it scares them. Don’t know why. So we have limited it for now to a simple “user context” which only identifies the user and login state. But not for example which order is active, or any other stuff which would be handy to memorize centrally. We could improve performance of the whole site considerably by putting some key attributes in the session. It would save doing lots of database calls in lots of places. So we will first go live with a “simple” version of solution C, and then later see if we can convince them to add some extra data for speed.
Last technical note on solution C: Initially the plan was to build it using envoy as ingress replacement, and use a LUA script in envoy to call a Kotlin service to handle the session lookup and mutations. But, in the mean while we also were rebuilding the API gateway, using spring cloud gateway (using netty + async), and that did prove to be fast, robust, and easy to extend. So in the end we chose to do this new proxy also using spring cloud gateway (in Kotlin). Also because we have lots of Kotlin developers on the project to maintain that code, and not many with envoy/LUA knowledge. For session storage we will test with PostgreSQL (which has proven itself in our IDP), and with MongoDB, and Redis. We will start with PostgreSQL, as I expect it to have the best performance for this use case, but… I might be wrong, and we might find out that one of the others is better. A nice Gatling performance test script, together with Perfana and Dynatrace will let us know. I did actually also try using Nginx (ingress) to do the session handling with it’s LUA capabilities, but that won’t work. We need to lookup and modify stuff after the proxy response comes in, and Nginx does not allow to call remote services in that phase. It only allows you to do that before the proxy call is executed. A small proof of concept with envoy showed that it would be possible to do it with envoy also.
That’s it for (the final) part 6 of the series.
Thijs, December 27, 2020.
All parts of this series:
- Part 1 – Overview
- Part 2 – Gateway
- Part 3 – IDP
- Part 4 – Oauth2/Scopes
- Part 5 – From Legacy Monolith to Services
- Part 6 – Oauth2 and Web