Find Kubernetes Ingress Rules
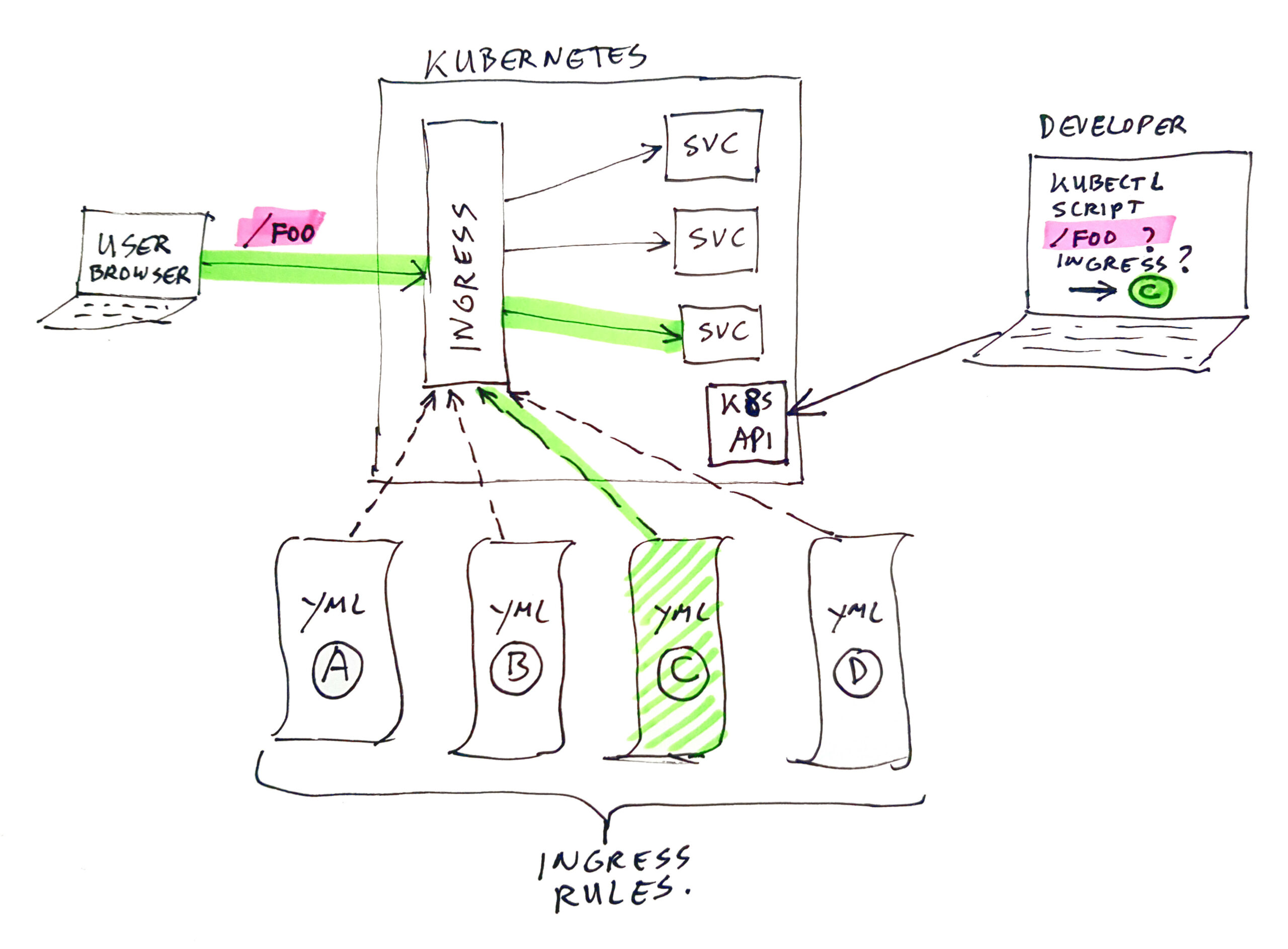
Suppose you have a kubernetes cluster, which contains a large set of ingress rules, of which many are used for the same hostname (just using different context-root’s / paths). In this case it can be hard to find out which rule is used for a certain URL. To help out in this situation I have created a Linux script to make a nice overview of paths mapped to what services by which ingress rules. You still have to read through the list to find the proper entry for your URL, but it is much quicker than searching through a bunch of YML files.
See GitHub repo: https://github.com/atkaper/k8s-find-ingress
The GitHub README explains how to install the script, and what dependencies (tools) are needed. In this post, I will try to explain the inner workings of the script.
Example Run
Let’s start with an example run, against the test data as provided in the GitHub example-rules folder:
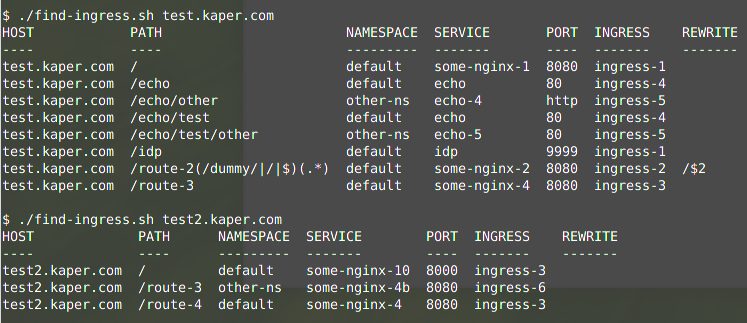
As you can see in above examples, it is possible that some paths are overlapping. In that case, ingress will use the “best / most-specific” match for each URL to process.
For example “test.kaper.com/hello” will end up in service “some-nginx-1” in the default namespace, as result of ingress rule “ingress-1“, as it matches path “/“. And “test.kaper.com/echo/test/hello” will end up in service “echo” in the default namespace, as result of ingress rule “ingress-4“, as it matches path “/echo/test“. That “/echo/test” is more specific than the two others which also math: “/” and “/echo“.
In the current version of the script, you will have to do this URL to path/rule matching yourself, by just reading through the table. But as mentioned before, the table view make this much easier as when you had to dig through many many YML files with the “raw” ingress rules.
Detailed Explanation Of The Script
The contents of the script:
#!/bin/bash
# This script lists all ingress rules for a given hostname.
#
# To use this, you need to have some tools installed:
#
# - kubectl : to query kubernetes
# - jq : to process json (a recent version, older versions do not know about $ENV handling)
# - column : to format data in a table
#
# Only tested on linux.
#
# Thijs Kaper, July 8. 2021.
if [ "$1" == "" ]
then
echo "Usage: $0 hostname"
echo "Example: $0 www.kaper.com"
echo
echo "The following hostnames are available:"
echo
kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec.rules[].host' | sort -u
exit 1
fi
export HOST=$1
(
echo "HOST PATH NAMESPACE SERVICE PORT INGRESS REWRITE"
echo "---- ---- --------- ------- ---- ------- -------"
kubectl get --all-namespaces ingress -o json | \
jq -r '.items[] | . as $parent | .spec.rules[] | select(.host==$ENV.HOST) | .host as $host | .http.paths[] | ( $host + " " + .path + " " + $parent.metadata.namespace + " " + .backend.service.name + " " + (.backend.service.port.number // .backend.service.port.name | tostring) + " " + $parent.metadata.name + " " + $parent.metadata.annotations."nginx.ingress.kubernetes.io/rewrite-target")' | \
sort
) | column -s\ -tCode language: Bash (bash)Note: there are some looooong lines in above code, you might want to scroll horizontally to see it all.
- The
if [ "$1" == "" ]checks if you passed in a parameter, and if not, it displays some help text. - Inside that “if”, there is also this line:
kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec.rules[].host' | sort -u
Which asks using kubectl for ALL ingress rules in ALL namespaces, and it gets that as JSON data.
Next that is piped through “jq” the json parser. The expression for “jq” walks though all “items”, finds their “spec” node, and walks through all “rules” in the spec, and takes the “host” value from there.
As last step, the list of hosts (which can contain duplicates) is send through “sort” with the “-u” show unique results option.
If you don’t know “jq”, you can try building up above line by doing that in small steps:kubectl get --all-namespaces ingress -o json#(to list rules in json)kubectl get --all-namespaces ingress -o json | jq -r '.items[]'#(to see items as separated array elements)kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec'#(to see just al spec parts)kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec.rules[]'#(to see rules)kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec.rules[].host'#(to see just host field from rules – this shows duplicates in many cases)
And finally add the sort -u to it…kubectl get --all-namespaces ingress -o json | jq -r '.items[].spec.rules[].host' | sort -u - The
export HOST=$1just copies the first command line argument to the HOST environment variable. This will later be used from within “jq” by using “jq” expression “$ENV.HOST”. - The next interesting “trick” is putting some statements between round brackets. The round brackets “collect” the standard output from the separate statements, and allows us at the end to pipe that through another command.
Take for example this command set:( echo y; echo x; echo z ) | sort
It echo’s y, x, z (on separate lines) – not on screen, and collects that as single output stream, and sends it through sort to show result x,y,z on screen (on lines below each other). In the script I use this to construct a header and header separation line, and combine that with the data output, and afterwards send it through the “column” command. It needs to be combined with the data, because the column command will make each data column the exact width to fit all records nicely. And we want the header to line up above the proper column (e.g. use the same column width determination). - After the header display, the
kubectl get --all-namespaces ingress -o jsoncommand will read ALL ingress rules for ALL namespaces for the cluster in context. The data is outputted as json. - The json is piped though the
jqcommand, to filter only interesting results, and format them as one row per path, with each field space separated. The “-r” on jq indicates that we want “raw” data, without quotes around string values. The jq “query” is quite long. It’s parts are separated by pipe symbols, where the output of the data is send to a next processing step each time. I will go through all separate filter steps for the jq expression now: .items[]this iterates of all separate ingress rule definitions. So one yml file per next filter step.. as $parentthis sets a pointer to the current “node”. This allows us to reference back to this when we are later in filtered results which do not have the parent fields anymore..spec.rules[]this walks though all rules in the spec section. Here’s an example of one of these rules[] entries, to clarify the next steps:
{
"host": "test.kaper.com",
"http": {
"paths": [
{
"backend": {
"service": {
"name": "some-nginx-2",
"port": {
"number": 8080
}
}
},
"path": "/route-2(/dummy/|/|$)(.*)",
"pathType": "ImplementationSpecific"
}
]
}
}Code language: JSON / JSON with Comments (json)select(.host==$ENV.HOST)This select is a filter, which only passes on records for which the host value is equals to the value fo the HOST environment variable. The$ENVis a virtual variable in jq, which gives access to the shell environment. Earlier, we did set the value of HOST to the value of the first command line argument..host as $hostThis memorizes the value of the host node. Next filter will be zooming in to deeper levels, but I wanted to show the value of the host also in the end result..http.paths[]walks through all paths entries. Above example shows only one, but there can be multiple.( $host + " " + .path + " " + $parent.metadata.namespace + " " + .backend.service.name + " " + (.backend.service.port.number // .backend.service.port.name | tostring) + " " + $parent.metadata.name + " " + $parent.metadata.annotations."nginx.ingress.kubernetes.io/rewrite-target")Ok, this one is a bit too big to do in one step 😉 Let’s split it apart, this time on the + sign. The plus is a simple string concatenation, to produce the total output. The obvious+ " " +I will skip, that just adds a space between values.$hostthe earlier mentioned value of the host attribute..paththe source path expression, used to match your url path.$parent.metadata.namespacethe namespace of both the ingress rule and of the destination service. Taken from the earlier stored parent node data..backend.service.namethe service to which the path routes its request.(.backend.service.port.number // .backend.service.port.name | tostring)interesting construction. This reads the port number of the destination service. The//is an expression which chooses either the value before it if it is defined, or if it is not defined, then it gives you the value after the //. So if there is NO port number, then it will find the port NAME. As string concatenation using + signs can only work with strings, and not with numbers, the last part| stringis a built in jq filter function which converts numbers (or strings) to strings. This allows us to concatenate the port number in the end result.$parent.metadata.nameis the name of the ingress rule. So when combined with the namespace value, you should be able to find the ingress rule.$parent.metadata.annotations."nginx.ingress.kubernetes.io/rewrite-target"this shows the value of an annotation on the ingress rule set. It uses the parent reference to get there. The shown value is used to determine a rewrite of the incoming path. If NOT defined, the destination service will get the same path as the source URL used. If defined, the service will use the defined value as destination. If you use a $1, $2, … in the target, it is replaced by the regex groups as defined in the “path” values. Example: ifpath = /test(.)/(.*)andtarget = /foo/bar/$2/$1/barthen URL path/testX/Y/Zwill lead to service call/foo/bar/Y/Z/X/bar. Note, we mainly use this to translate path prefixes, e.g.path=/static/image/(.*)target=/img/$1. Although MY personal preference is that you do not translates paths anywhere. Just make your service respond to the original source path if possible. Saves you lots of trouble/complexity later.- That’s all the jq filter parts. When broken down, not too complex anymore, but when seen as one big line it’s quite challenging 😉
- Next step:
| sortwill sort the end result rows alphabetically. Host name is first, but same for all rows, so no influence on sort. Second field is the path, so effectively we are sorting on path. So / goes first, then /a, /b, etc… - Last step:
| column -s\ -tthis pipes the end result as was between ( ) to a fixed format table. you do need to look at the result with a fixed width font of course. The column command measures the width of each column’s data in all rows, and then pads all fields to be the proper width to fit in the column. The “-s\” (note the extra space after the \ !) indicates we look for space separated field values (note; you can leave that “-s \ ” off, it is the default), and the “-t” indicates we want it shown as a table. If you want to play around with the column command, try this for example:( echo X Y; echo XXX YYY; echo XXXX YYYY ) | column -s\ -t.
It determines that the last row is the widest, and makes a table using that size, so this is the end result:
$ ( echo X Y; echo XXX YYY; echo XXXX YYYY ) | column -s\ -t
X Y
XXX YYY
XXXX YYYYCode language: Bash (bash)Conclusion
A useful little tool (in my humble opinion).
A nice improvement would be to rewrite the tool in for example Go-Lang. This will allow it to be usable on multiple OS-es perhaps. Another possibility when using Go-Lang might be to add the option to pass in a full URL to the tool, and just show the exact matching ingress rule as result. This will require implementation of the same algorithm as NGINX uses to match path expressions, and pick the best matching one.
Another future addition (in shell or Go-Lang) could be to show which rules force SSL/HTTPS. In the past, we sometimes had issues if all rules are NOT supposed to force redirect to HTTPS (e.g. when we have a load balancer in front which handles SSL offload), and then someone by accident deploys a rule which DOES force redirect to HTTPS. That single rule breaks the whole site (causing an endless redirect loop), and needs to be found quickly 😉
Thijs Kaper, July 9. 2021.
One thought on “Find Kubernetes Ingress Rules”
Great script and post !