Micro-services Architecture with Oauth2 and JWT – Part 5 From Legacy Monolith to Services
The last number of years I have been working in the area of migrating from legacy monolith (web) applications to a (micro) service oriented architecture (in my role of Java / DevOps / Infrastructure engineer). As this is too big of a subject to put in a single blog post, I will split this in 6 parts; (1) Overview, (2) Gateway, (3) Identity Provider, (4) Oauth2/Scopes, (5) Migrating from Legacy, (6) Oauth2 and Web.
Introduction
Lets start by defining the two items we are talking about; the Legacy Monolith, and the Micro Services Architecture. Both of these provide a web site for the end-user. The end-user should not be aware of the different implementations. It’s all happening “under the hood”.
Legacy Monolith
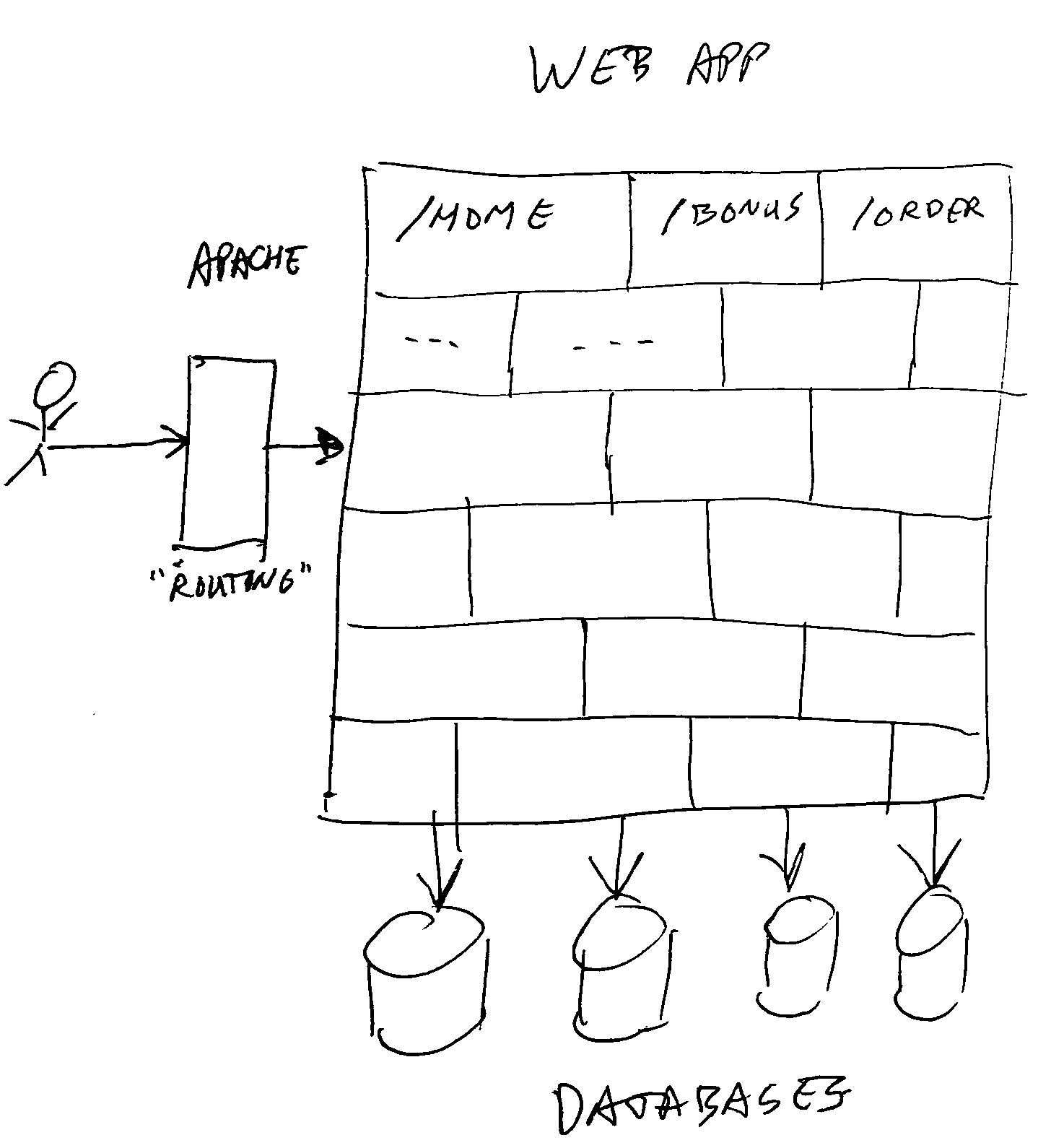
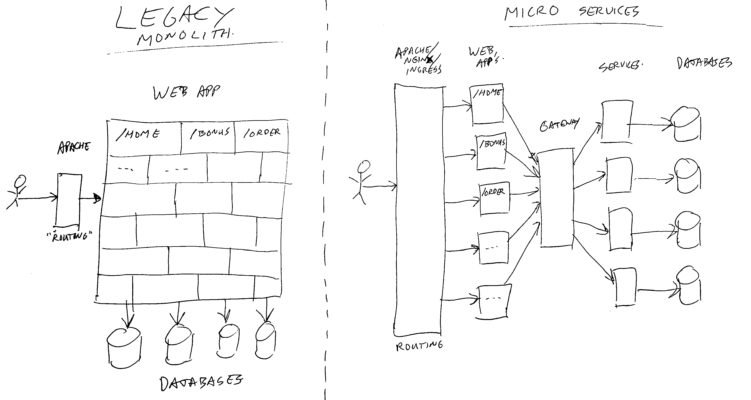
A monolith is (in this case) a website application, consisting of ONE BIG deployment. In other words, if you want to install a different version of the website, you just take a single file, and put it on the server and start it. The single file app will serve all web pages for the user, and knows about all business logic, and talks to one or more big databases.
If you need to scale up to keep up performance when handling more customers, you just install more copies of the same file on multiple servers, and put a load-balancer with sticky sessions in front of it. This way each instance will handle a part of the customer traffic.
The sticky sessions will cause each customer to end up on the same copy of the app for each request. This way the app can cache data, and keep a session active for a user. (Note: of course in monoliths, you can also store sessions in a database, and use distributed caches, if you do not want sticky sessions – but that’s not the point of this story).
Our monolith consists of java, spring controllers, mainly renders HTML with placeholders to get dynamic data, and does run on tomcat on Linux virtual machines.
Inside the monolith, we used lots of “components”, each handling a functional area, and they consisted of controller layers, services, data access layers, and similar components. Each area was stored in it’s own git project, and building the application would put them all together in a single (web-archive – war) file for deployment in tomcat.
Some pro’s and con’s of using a monolith:
- Pro: simple installation of any version on the server. Easy rollback if problems arise with a new version.
- Pro: if you need another test environment, just install a new server with the same application (or a different branch/version of it), and point a new host/domain name to it. You can also simply point each test copy to different test databases if needed (or to the same test database).
- Pro: all internal component layers are compile/build time connected, so there are no mismatches in interfaces possible.
- Pro: components/layers have no latency in executing calls from one to another, as they are all in the same code-instance/VM.
- Pro: debugging an application where you run all code on your local machine is relatively easy.
- Pro: having all code on running on your machine also means you can test every part of the web-site.
- Con: If the web app gets big, you have lots and lots of code, which all has to run in the same machine. This may need lot’s of memory and lot’s of CPU. Mostly not an issue on the server, but on your local laptop might become a challenge.
- Con: If the web app gets big, constructing/building it on your development laptop might take lots of time. I remember that if you did a clean install (of all parts), you could easily go and drink some cups of coffee before you could use the app.
- Con: If the number of developers gets big (many teams), it becomes much harder to all work on the same code-base. Even though we did split everything in separate modules and git projects, it would become increasingly difficult to glue them all together on your machine to run, as interfaces of multiple modules were changing at the same time on different branches.
- Con: separating front-end development and back-end development was difficult. Later we also split front-end into separate git projects, but again, connecting the proper versions of front and back to each other was a challenge. And no compile/build time checking in there.
- Con: building a huge set of modules / git projects requires you to run all of their unit tests also. Building speed (or lack of speed) was no fun.
Of course there probably are more pro’s and con’s. But these ones were the first which came to mind.
Micro Services Architecture
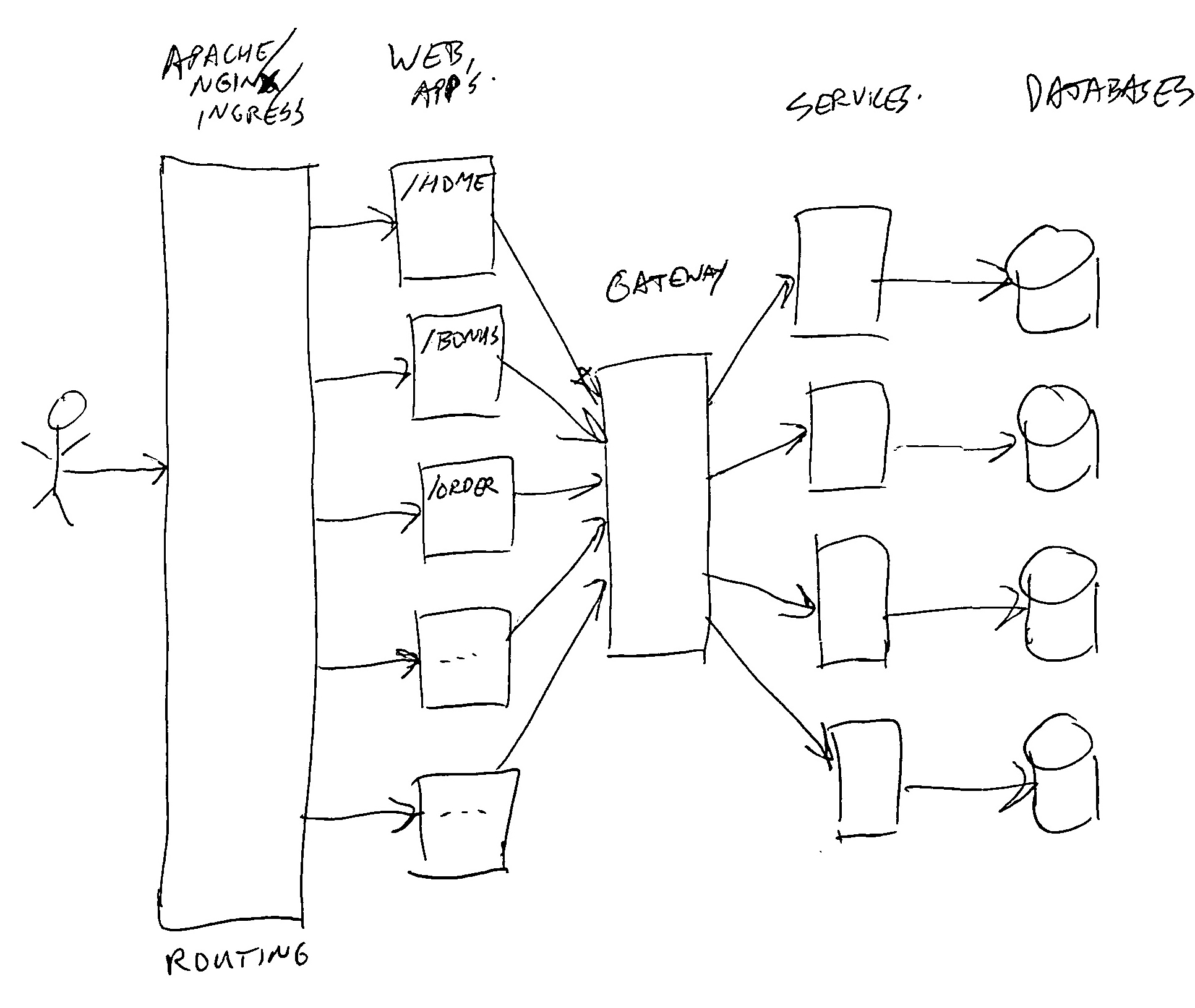
What happened in this image, is that all the parts of the old monolith are put in separate blocks. Every customer web request which comes in, is split by looking at the URL path’s (context root), and send on to the proper web application to be handled. Each web application is a small part, only responsible for rendering a couple of web pages. No longer do they know how to render the whole website. Each web-app also does not know how to talk to databases, and does not have much business logic. Mainly logic to handle flow from one page to another, and to render data in the proper way.
When a web-app needs data from a database or other system, it will talk via a gateway to the proper services, and each service has it’s own (possibly smaller) database or other data system. Also the more complex business logic is put in services.
The image is a simplified setup. In real life, there are more layers. For example facades, which are components in front of services to combine data from multiple services into one call, and to transform or filter data.
In the end, the same sort of code, storage, and business logic is available in the combined parts of the Micro Services Architecture. But this time everything is installed as separate pieces of code, running in separate containers, mainly talking to each other via HTTP requests (web, GraphQL, and rest-full), and the bottom layers mainly via SQL connections.
The web-apps (front-end) are (in our environment) mainly build using Node.js / Reactive (not my knowledge area). The gateway and services are (in our environment) mainly build using Kotlin/Java, with spring-boot.
All of the above is deployed as docker containers in a Kubernetes cluster, where each part can run with 1 or more copies/instances, depending on the needed resources to handle the load.
In this distributed setup, there is no session stickiness. So all parts are stateless. Where there is state, it is stored in databases. This allows us to dynamically scale up or down for each part. And it allows us to do rolling deploys of new (or old) versions.
Our current setup heavily uses Oauth2 to talk from front-end to services. Where the gateway translates the Oauth access token to a Json-Web-Token (JWT) with some caller context. See also the other parts of this blog series for more info on that.
Some pro’s and con’s of using a Micro Services Architecture:
- Pro: each component lives in its own (mostly small) git repository.
- Pro: quick to build (a single component).
- Pro: easy to deploy new version (of a single component), due to use of containerized platform.
- Pro: easy to run one component locally, and test just that one part. Does not need many resources. (Con: less coffee breaks?)
- Pro: easy to debug a single component.
- Pro: each component has limited responsibilities.
- Pro: easy to give each development team ownership of a set of components (while still allowing pull-requests on their code done by other teams). So this allows to scale up the number of developers.
- Pro: having separate web-app containers, and service-containers also nicely splits the front-end and back-end work and dependencies.
- Pro: scaling can be done per component, where with a monolith its scale all or nothing.
- Pro: if a single web-app has something nasty broken in it, the rest of the web site still works.
- Pro: by putting everything in services and facades, we can also expose the data and functionality to multiple touch-points. So we can use them for both web and mobile-app’s, and third party applications. In other words, we have created a partly open API.
- Con: services need a form of security to prevent them from being abused. (Which makes talking to them more complex).
- Con: you can not run the full web-site on your local machine. But… you can run parts of it, and “proxy” or “connect” the other parts to one of the test environments. So this gives you the illusion of having a fully working site. This however always involves “tricks” to get it sort of working.
- Con: if you need another (fully working web) test environment, you can not simply copy a piece of code… You need to create a complete new cluster, with ALL components. Which is expensive, and takes a lot of time to deploy (if there are many components, as we have).
- Con: all interfaces between components are NOT checked during compile/build time. So at run-time you can run into nasty surprises of incompatible interface changes. We try to mitigate this by always keeping one or more compatible versions of the old interface. And try to get the caller to migrate to the new version before removing the old. But… of course this sometimes goes wrong. There are also ways to do contract-testing, but it seems difficult to get a mindset for everyone to get that off the ground. So we are not there yet.
- Con: each component calling another one does have some latency, due to having to do an HTTP call to the next in line. Not a big delay, but it’s there.
- Con: because you need to call other components, this can mean you will get back unexpected network errors. You have to cope with these. In a monolith everything is internally connected, so an internal call never fails.
- Con: debugging the full application is not possible anymore. To get some insights, we make sure that we log all messages using a correlation-id. This is a unique number, generated per end-user web request, which is passed on on each layer call, and logged together with all messages. Also we are using the “Dynatrace” product. It does instrument ALL parts of the system, and provides you with a GUI to look at all call paths, delays, errors, and so on. A super nice product (but expensive). You can also look into using Zipkin or other tracing libraries, if Dynatrace is out of reach.
- Con: as the site consists of lots of components, on a test cluster there is always the chance that one or more components are temporary broken, due to new developments. This breaks a fully automated test of the whole site on the test environment. Of course we should create a new mindset: test smaller chunks, start with testing each component separately (which is done during build time of course). But again, this would for example require having mock versions of the components around the component under test. This is not as simple as it sounds, and also is not fully operational where we are. So integration testing requires all to work.
- Con: performance testing is a bit more complex, as there are many separate components, which can each be scaled up or down. (Where the Pro is that you can scale each part separately up or down).
Again, there probably are more pro’s and con’s.
Web Application Migration Strategies

Migration from legacy to new architecture can be done using the so-called “strangler” pattern. You can find quite some examples of that on the internet.
Basically this means that you route part of the traffic to the legacy application, and part of the traffic to new applications. And each time you make something new, you move more traffic to the new applications, until the old one is not needed anymore (strangled).
We have multiple legacy applications, and they were done using different strangler-like patterns.
Open Strangler
For one of our legacy applications (the main website) we made the choice to build new micro-services, and when adapting legacy code, call the new services instead of building/altering functions locally. We basically moved service code out of the monolith.
Next to this, we also did rebuild front-end website sections by overlaying URL paths / pages to point to new platform web-app’s & bff’s (back-end for front-end), and use new services from those new web-app’s.
In this case, we also did choose to delete unused / dead code from the monolith, to make it smaller each time.
Cleaning up parts of the legacy monolith has some effects:
- Positive – less code – build faster.
- Positive – less code – use less runtime resources.
- Positive – less code – left over parts more maintainable.
- Positive – no errors from updated (removed) database stored procedure calls.
- Negative – the will / ability to update monolith – has risk of “quickly” doing new feature changes in the legacy code. That’s a big NO! Stand up to your product-owner… New features must be build using new architecture components.
- Negative – having to remove dead code seems a bit useless if you will throw away the whole thing later anyway.
Why did we choose to do this cleanup? I guess mostly because the migration is a multi year project. But if I had some more say in this… I would “close” the code more, and go for the next option.
Frozen Strangler
For another one of our legacy monolith’s (a rest server for mobile app’s, no web pages), we did choose to do it differently.
In this case we followed the classic strangler pattern a bit more.
New services were developed for every new piece of functionality. And also when we needed to change functionality, we created new services for that.
No (or very little) changes are done in the legacy code, and a special proxy has been placed in front of the old and new code. It decides to route the call from mobile app to the proper back-end (old or new). And some security / authentication / authorization helper calls were implemented in the new proxy.
Frozen strangler effects:
- Positive – no code changes in legacy – does not feel like doing useless cleanup work.
- Positive – no code changes in legacy – very clear to product owner that new features will NOT go in legacy code.
- Negative – no cleanup – no resource nor build time saved.
The differences between the two stranglers are not that big, but for me the frozen one sounds a bit more effective. But each has it’s use.
Routing
The strangler patterns both need some special routing in front of it. We used a set of different options:
- Apache HTTP server – for our main website this chooses between legacy monolith tomcat and Kubernetes platform. It has some “balancer” pools pointing to different back-ends using proxy rules or rewrite rules. And it also serves a bulk of product images from the filesystem of this server.
- Zuul (a Netflix Library for Spring-Boot) – This chooses between legacy monolith tomcat and new services landscape, it is used for the mobile app’s. We will soon remove this mobile specific router, and point that traffic to the API-Gateway.
- Nginx / Ingress – This routes to new web containers inside the Kubernetes clusters. This is part of the standard Kubernetes architecture.
- API-Gateway (we were using Zuul, but have just moved to Spring-Cloud Gateway this month) – This routes traffic from web-app containers to micro-services, and it provides an entry for external use, and for mobile app’s.
The most obvious choice in routing is not in above list; the internet facing load-balancers. If you have the chance to split the routing in there, then by all means, go ahead. It will have the least delay/latency. We decided against using those, as they are maintained by another department, requiring tickets for changes to them, and the changes are manual instead of via some API. We change routes regularly, so having that done by some nasty procedure is not an option for us. If you go that way, use an API, and automate all mapping changes.
In the (near?) future, all customer traffic will end up directly on the Kubernetes clusters. No Apaches in front of it, and Kubernetes will handle routing using Ingress/Nginx, Spring-Cloud Gateway, and for web via a custom proxy component (similar to Nginx/Ingress, but with session persistence and customer context options).
Database Considerations
In the legacy monolith world, we are using a small set of big Oracle databases, and those big databases do contain lots of tables, triggers, and stored procedures.
In the new micro service architecture, the services can use new (mostly smaller) databases. We use for example MongoDB, Redis, and PostgreSQL. But quite some services still have to use the big old Oracle databases also for a while.
Lots and lots of functional areas and business logic are interwoven in those old databases. We have a special team looking at splitting off pieces of functionality, and moving of business logic from the stored procedures into Kotlin services. When most logic (and queries) have moved to the new services, we can also see if we can move parts of the data for these services to their own database. This way we try to dismantle the old databases bit by bit. A sort of strangler pattern for the database.
In theory the end state should be that each service takes care of it’s own database, and is the only one managing the data in there. So we should not have multiple services talking to the same database.
Why should each database have only a single service as owner?
- To prevent abusing the database as transport between services.
- To prevent hidden magical data mutations (good or bad).
- To give a service full control about what to cache, and what not, without having to worry that some other service queries stale data in the underlying tables, or changes data which is not reflected in the cache.
- To give a service development team freedom to switch to use a totally different storage back-end if that better suits the situation, without having to inform service users.
- To be able to scale each database as suitable for the service which uses it.
- To not have a single point of failure in case the big database has some downtime (both planned and unplanned).
Unfortunately our Oracle databases are quite big / complex, so I expect this split up to take many years, if it will even ever be completed. It also requires a shift in developer skills (in the DB teams), from only database centered to more Kotlin/service combined with proper SQL knowledge to keep good performance.
Closing Thoughts
So what are my preferences? Use a monolith, or create a micro services landscape? This actually heavily depends on the situation.
When you have a small team maintaining the code, and you know your team will not grow any time soon, then you probably are better of using a monolith. It’s simple to build and deploy, and has no latency in talking to itself 😉 And it’s probably much cheaper to run with respect to needed infrastructure and servers.
But… if you are working with multiple development teams, or it looks like you will grow into that situation any time in the near future…. Then you are probably better of building your code using micro services, and separate web-app’s. That’s easier for splitting the work in that case. However, when going this route, you need more complex hardware and infrastructure, and you will need one or more dedicated teams to maintain the cloud platform. This situation will be much more costly than the monolith version.
As for migrating from monolith to micro services; if you ever get yourself in that situation, I would advise to try and migrate everything as quick as possible. Of course in our case, we are working in a big / slow corporate organization. This means that we do not get enough time to migrate old stuff. In the end this will bite you. You need to keep running old and new together, causing lots of unwanted side effects or performance issues, and people not knowing where to look for code and issues. Not nice. Do it FAST.
And you probably guessed so, but the terms “Open Strangler” and “Frozen strangler” are just made up by me. But I think they nicely indicate what we mean by them.
In my opinion, the Frozen Strangler is preferred, but sometimes a change has too tight of a deadline to allow for rebuilding existing parts. But I would only do really small changes in the legacy code in that case, anything bigger needs to be done in the new style! And of course, if you need to connect your legacy code to new session or security mechanism’s, you might also need to do some (hopefully small) changes in there.
Database-wise; I’m not a fan of having too much logic inside the database. Triggers triggering other triggers which trigger more triggers, having lots of stored procedures with many code lines… In my opinion all a no-go. It makes it totally unclear what happens and why, and with what side effects. I would suggest to keep a database simple and without too much logic. Just the referential integrity if needed (foreign key relations), and value constraints if wanted. Also consider using other types of databases than SQL. If you work with lots of JSON objects you might for example consider MongoDB, or PostgreSQL with native JSON support. And even when making a new monolith, you could make use of multiple smaller databases, each having their own characteristics.
That’s it for part 5 of the series.
Thijs, December 25. 2020.
All parts of this series:
- Part 1 – Overview
- Part 2 – Gateway
- Part 3 – IDP
- Part 4 – Oauth2/Scopes
- Part 5 – From Legacy Monolith to Services
- Part 6 – Oauth2 and Web
2 thoughts on “Micro-services Architecture with Oauth2 and JWT – Part 5 From Legacy Monolith to Services”
Ben benieuwd of je nog steeds Zuul gebruikt Thijs? Komt er nog een artikel “een jaar later” ? 🙂
Hey Maarten, no we moved to use Spring-Cloud-Gateway (in Kotlin), which is mentioned in the article in short, but maybe you are right, and a new post should be added about current state of all 😉 Will do!