K8S Tiller/Helm History Cleanup
GitHub Project: https://github.com/atkaper/k8s-tiller-history-cleanup
Introduction
WARNING: This is about helm 2, in the old days… (2019) Please move to helm 3+, and do not use this old cleanup anymore 😉 Article just kept for historic purposes.
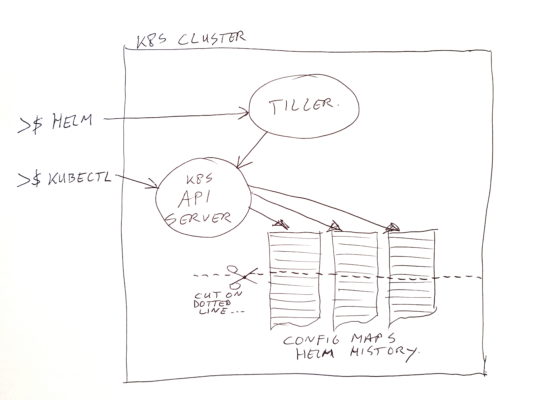
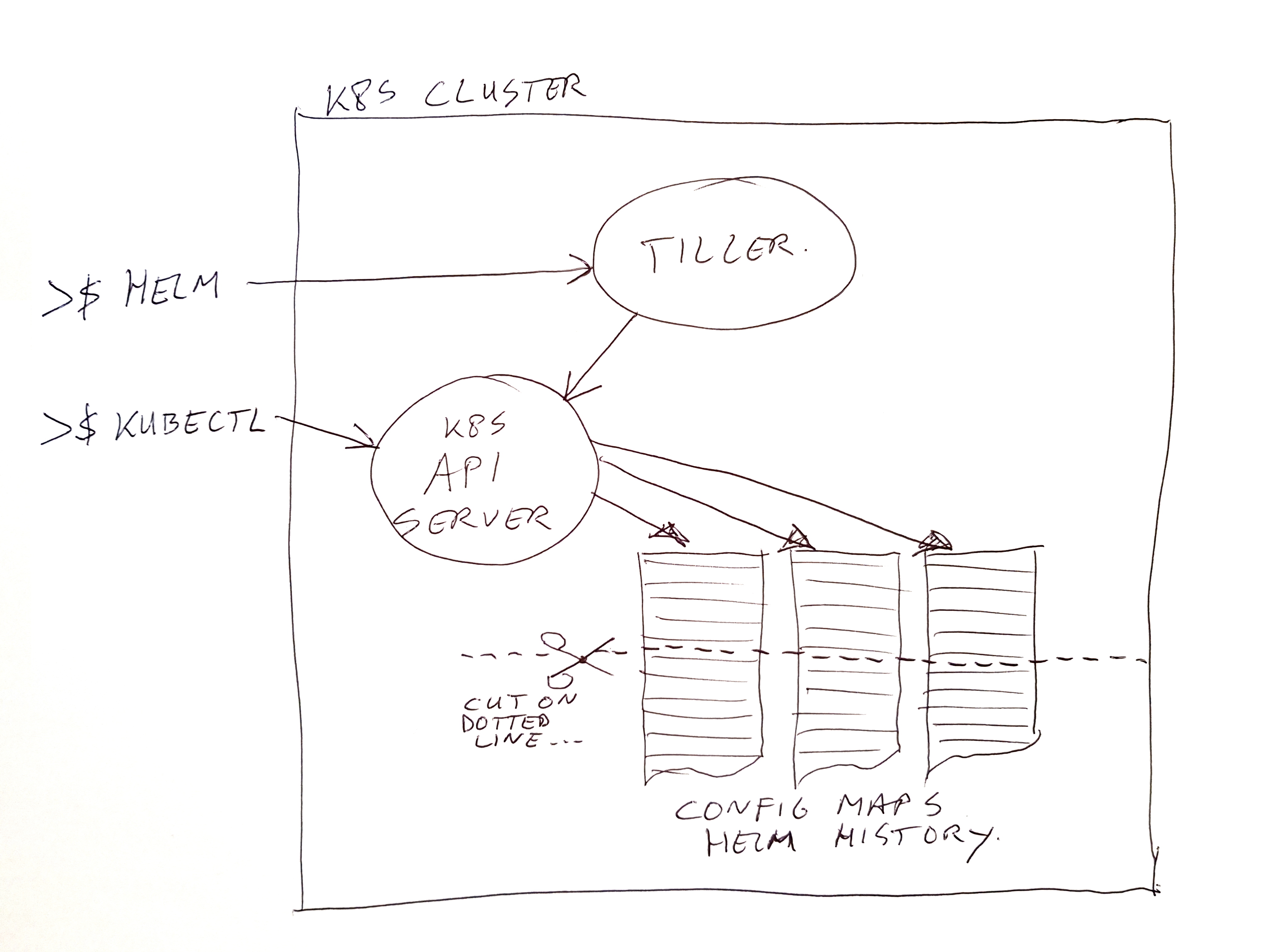
In our on premise Kubernetes cluster, we use Helm for a big part of our application / micro-services deployments. Helm uses an engine called Tiller (which is a deployment in the cluster). It executes the installs / updates / deletes, and it stores the results of deployments in the system as config maps.
While migrating our applications to a new K8S cluster, we saw that we forgot to set a limit on the history which is kept by Helm/Tiller. Oops… unlimited history is the default.
Of course it’s easy to change the history setting in Tiller from unlimited to for example 5. But it seems changing the value does not pro-actively cleanup the old data (or at least not in the version we use). It does cleanup the history for a single named release, when deploying a new version of such a release.
To execute a pro-active cleanup, I did write a small shell script. The script actually does more than just truncate the history. It also scans the cluster for active artifacts from Helm deployments. If none are found, then the complete history for it is removed.
If you use Helm to do your artifact deletions (with purge option), this would not be needed. In our case however, we create lots of temporary namespaces. One for each Jira ticket number for which a code change needs to be tested. And these namespaces are deleted (using “kubectl delete namespace <###>”) by a cronjob when the Jira ticket changes it’s status to resolved or closed. But of course this leaves you the Helm history entries, without the actual deployments being there.
Running the script
Let’s first start setting up the proper history length in the already installed Tiller deployment. For our cluster, I could do that using the following command:
kubectl edit deploy -n kube-system tiller-deployYour “favourite” editor will open, and then you can set the history size in the environment variable section, like this:
- env:
- name: TILLER_NAMESPACE
value: kube-system
- name: TILLER_HISTORY_MAX
value: "5"Code language: JavaScript (javascript)
2 thoughts on “K8S Tiller/Helm History Cleanup”
Nice work Thijs! Thanks!
Thanks for this, really helped me