Micro-services Architecture with Oauth2 and JWT – Part 3 – IDP
The last number of years I have been working in the area of migrating from legacy monolith (web) applications to a (micro) service oriented architecture (in my role of Java / DevOps / Infrastructure engineer). As this is too big of a subject to put in a single blog post, I will split this in 6 parts; (1) Overview, (2) Gateway, (3) Identity Provider, (4) Oauth2/Scopes, (5) Migrating from Legacy, (6) Oauth2 and Web.
(Note: This article has been updated a bit on the 17th of January 2020 – no more Hazelcast, and some more security).
Introduction
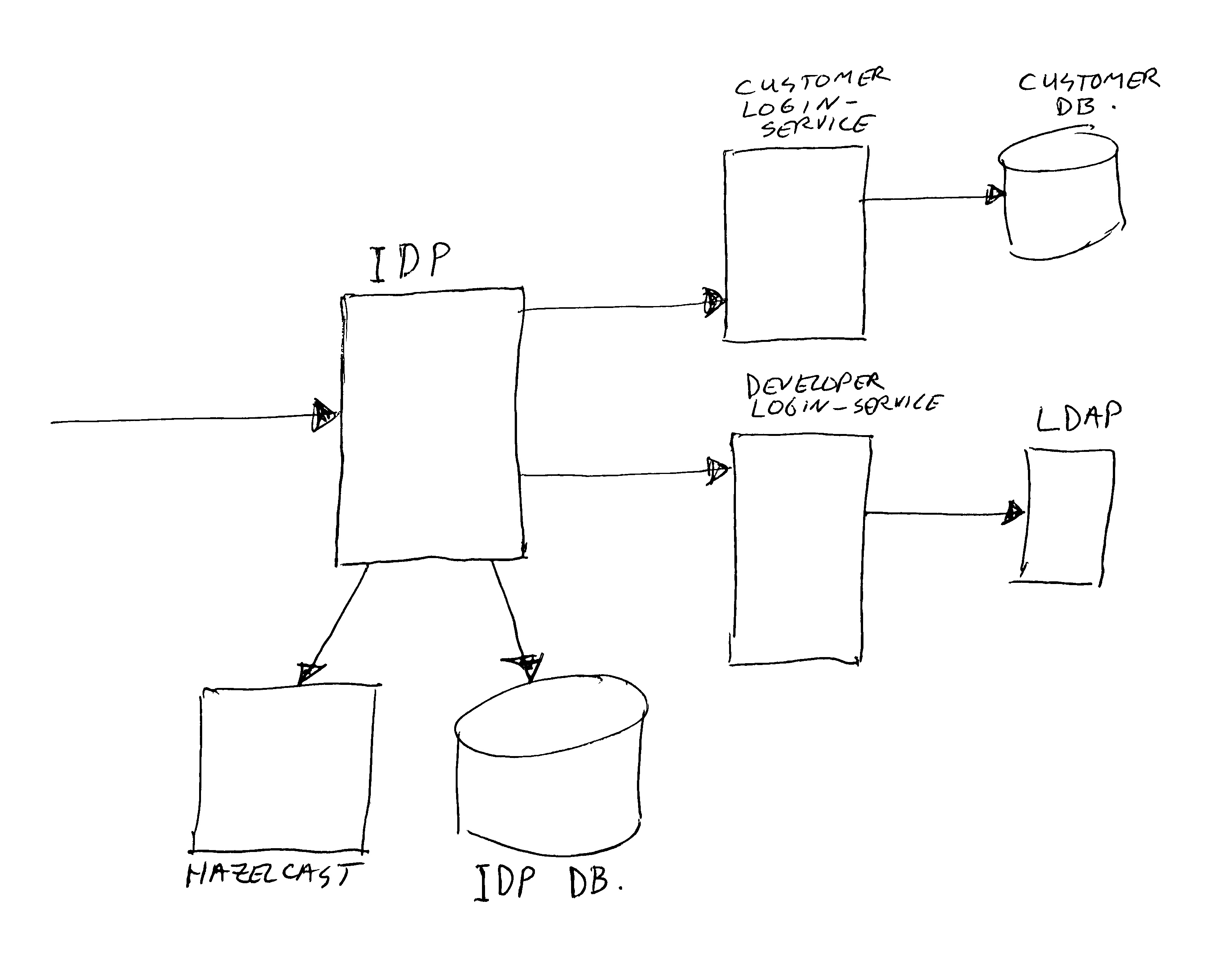
The Identity Provider (IDP) is the main component handling all Oauth2 scenario’s; creating tokens, refreshing tokens, checking token validity, authenticating users, converting tokens to JWT’s or to user-info.
For this we are using the spring boot authorization server (identity provider) as a base. We have quite heavily customized this component.
The standard authorization server was a good starting point, but in the years of usage we did have to solve quite some issues and add some functions.
If I had to start over, I would not mind having to write this thing completely by my self from scratch. Oauth2 is not that complex in it’s base. But on the other hand, using a standard library might save you from falling for some security holes, and at the start we were not that experienced with Oauth2 also.
I will explain Oauth2 (or at least the pieces we use) in the next part (#4) of this blog series.
Implemented Customization’s
Here’s a list of changes we made (in no particular order):
(1) Allow for having more than one access and refresh token active at the same time per use-case. Where “use-case” is the same combination of scopes, client-id, and user-id. The standard IDP did not allow for that. This change was needed for some of the later mentioned customization’s.
(2) Point (1) does cause unlimited growth of the number of tokens per user. To prevent that from running out of hand, we created a background cleanup task. It checks for a certain maximum number of active tokens per use-case. Currently we allow for 8 active access tokens and 8 active refresh tokens per case. Our initial cleanup implementation was a table scan with counting of number of tokens per case. But after some months, our number of tokens was getting so big, that a table scan every hour gave a negative impact on performance. So we changed it to use a memory queue to limit the checks to active use-cases. There is a small chance of losing such a memory queue, when we do a roll-out of a new code version. But that does not matter. If the user keeps executing requests, he/she will re-enter the memory queue. And if the user left at the same time as losing the queue (that’s a small time window!), then the tokens will get cleaned when they expire anyway by another cleanup batch job.
(3) Created a batch job to cleanup expired tokens. Most of our access tokens have a validity period of 2 hours, and many refresh tokens have a validity of 3 months. This is all configurable per Oauth2 client. The standard IDP did not implement pro-active token deletes. It kept them in the database, until the user came by again, and only deleted it when the user requested new access. We just have way too many users and new users to allow for not cleaning stuff up. And apart from registered users, we also have lots of short lived anonymous user access tokens.
(4) Allow for re-use of tokens in some cases, or no re-use for other cases. The standard IDP always tried re-using tokens, we made it configurable. And more importantly, when requesting a token (with re-use enabled), and an existing one is almost expired, we do not pass that one back for re-use anymore. That caused needless 401’s and refreshes. Perhaps token re-use is not such a good idea anyway, it possibly causes two app’s or two browser instances sharing a token (for the same user/use-case). But in the case of concurrent app or web actions, it also does help to actually do have re-use. The concurrent requests are for the same user session, so should get the same tokens. It’s a bit of a grey area. Perhaps the optimum would be to allow re-use if the token was created in the last couple of seconds, and stop re-use after that time.
(5) Allow for setting a fixed TTL (Time To Live) on a refresh token. Normally, when you execute a refresh action, you will invalidate the old refresh token, and get a new refresh and access token. The new refresh token will normally get a fresh TTL, which effectively extends your session. So if you keep refreshing before the expire time, you do not have to logon again. We did have a case where we wanted to limit the total valid login period to max 4 hours. You could implement this by disabling refresh completely, and setting access token validity to 4 hours. But we chose to (optionally) allow for the transfer of the expire date/time from your initial refresh token to the newly created refresh token. This way the same refresh mechanisms apply for this limited TTL case, as for the normal extending TTL case. You can do normal refreshes, until you run out of the original TTL, logging you out of the site. This uniformity kept our client code simpler.
(6) When refreshing an access token, we can optionally keep the old refresh token valid for a short (configurable) period of time. The standard IDP did invalidate the old refresh token immediately. Some end-users (like IFTTT = If-This-Then-That) do require this, and also for clients executing concurrent refreshes (using the same refresh token), this prevents needless 401 errors.
(7) IP-blocker. When asking for a token, using wrong credentials, count this as a failed attempt for the used IP address. Too many failures? Then we block the IP for a while, to prevent password guess attempts. Challenge was here to use a distributed cache (Hazelcast) to make sure all running IDP instances knew about the same block counters. Note: we have the plan to move this from Hazelcast to Postgres for this function. Hazelcast works fine, but is not as easy to monitor for usage and growth as just using a (super fast) database. And we are running a quite high traffic environment! (a big retail organization, with high traffic website and high traffic mobile app, and multiple brand stores). We are storing failed attempts in a Postgres table, and on each failure we count the number of entries to decide on blocking the IP or not yet. The IP block itself is stored in another table, which allows fast lookup before attempting a login. Whenever an IP address gets blocked, we send a message to our internal chat system (Rocket-Chat, quite similar to Slack), to notify us immediately. A short while ago, we have added some more IP block mechanisms, we now have configurable GEO-ip blocking, burst guess-attempt blocking, and burst user hack attempt blocking.
(8) User blocker. When asking for a token, using a wrong password multiple times for the same user, we block the user account. The user will have to issue a password reset request to get it active again. This is actually not really part of the IDP code, but is done some layers deeper in the database. But IDP does handle the response for this case.
(9) User-Info endpoint’s. These are used to provide a partial implementation of OpenID Connect. Depending on the active scopes for the used client, you get one or more pieces of user-data when requested. If a third party wants to request this user data, then the user must first grant this permission as part of the so-called 3-legged login flow. The next blog post part (#4) will explain a bit more about that flow.
(10) Performance improvements (especially the endpoint which is used to check the access token validity for every gateway request).
(11) Custom attributes on the client definitions to influence IDP behavior per connected application. Actually, the storage for this is standard available, we just started using it.
(12) Custom login and grant screens for the full 3-legged Oauth2 login and grant flow. We support multiple organizational units / brands, each having their own end-user registration. They use different styles and different links to privacy and usage statements, and different links to forms to create an account. We can configure the branding to user per client.
(13) To get the login and grant screens working in a clustered non-sticky-session multi instance environment, we needed to add session synchronization. We started off with using Hazelcast for this, but later on we moved to use a Postgres database.
(14) Added support for multiple authentication databases / services. We can configure per Oauth2 client which authentication service to use. This is to separate the different brand web end-users, and we also have an authentication service using a corporate identity provider, and we have one using our developer LDAP server.
(15) Added a custom grant_type (=way of authenticating), to create customer-specific access tokens for trusted internal callers (for some use-cases where we do not receive the user’s credentials, but need a token for the user).
(16) Added a custom grant_type to exchange an external JWT for an access token. The external JWT is signed and checked using public / private key pairs. We also added a batch job to warn for almost expiring public keys.
(17) Scope groups… You can define scopes which are allowed to be used by a client. But we found that it was sometimes much easier to group scopes together, and give the scope-group to the client. This allows for the client definition to stay the same, while for example adding new scopes to reach newly build services. The scope groups are expanded to their nested scopes when creating the JWT. So the expanded scopes can be used by the gateway for allowing access to certain route-endpoint-mappings, and can be used by the services to check for proper authorization.
(18) JWT generation. The gateway does exchange access tokens for JWT’s. This is to give all our services a nice end-user-context, without the services having to talk to the IDP. Which in term is better for performance. But even though the gateway is the one exchanging the access token for a JWT, it is not the one computing the JWT. We have put that code in the IDP, because the IDP knows all about the end-user and the allowed scopes.
(19) We changed the authorization data block storage from serialized Java objects to simple JSON strings, in both the refresh token table and access token table. The serialized Java objects were insanely large, causing us to slow down. And it used way too much disk space, causing backup and restore taking too much time. Switching to JSON did decrease it’s size drastically.
(20) To monitor IDP usage and statistics, we have added some custom measurements / counters / statistics. These are read using Prometheus, and plotted on a monitor using Grafana.
(21) We have added the invisible Google ReCaptcha to the 3-legged oauth login screen to prevent distributed automated botnet attacks on password guessing. When Google thinks it is needed, it will show a photo puzzle to solve. Google ReCaptcha is easy to implement, you add some code to the HTML login page, and on submit in the server side, you call a Google API with the result of their check to see if it was OK. The server side check has been implemented in a similar way as the CSRF check filter, which is standard in the IDP. CSRF is also enabled on login and grant screens.
(22) We already did log all our success and failed login attempts to our ELK stack. But for faster querying/reporting on this data, we added a dedicated login audit trail in an SQL table also.
In the IDP we also have some more customization’s of importance for just our situation, not worth mentioning. The most important ones are listed above already.
Planned Customization’s
Even though the above list is quite big already, there still are customization’s which are still on our to-do list:
(1) Disallow Oauth2 requests where credentials are send as query string parameters. Currently the standard spring code does allow creation of Oauth2 tokens using query string parameters with client-secret and/or end-user’s user-id and password. These confidential parts of data should be send as POST body. If you allow these as query string, those fields do end up in access logs, readable by support technicians / DevOps engineers. For now we made sure no one is using query strings by just telling them not to, but it would be much better to disable the possibility completely.
(2) Investigate using something else than a Postgres database for token and client configuration storage. Postgres has proven itself to be blazingly fast, and very very stable up to now. But… it is running on a single machine. No replication, no master / slave. We do run regular backups, so in case of calamities, we can quickly restore these, or even restore to a different server. But this will lead to some downtime. In the quickest scenario probably 45 minutes, but for a server rebuild possibly some hours. And the tokens created in the time between backup and crash will be lost. We will investigate multiple options. Either a multi-master SQL database, or a document storage database like a MongoDB cluster (IDP can live fine without relational connections). Note: there’s no fear for hardware failures; we use virtual servers, which are replicated to a second data center, and the virtual server can move to other blade servers while running. So the High Availability setup is more of interest to be able to do maintenance on the OS, and allow for reboots without customer impact.
(3) Add an endpoint which is not publicly available, but just inside our data centers, with which you can ask for a JWT without having to first create an Outh2 access token. This can be done by internally combining the two needed calls into one. So you need the same kind of input as for creating a client-only Oauth2 access token, but in this case you would get a JWT instead of an access token. Why? Our API gateway (see part 1 and part 2 of this blog series) exchanges access tokens for JWT’s when calling facades or services on behalf of an end-user or application. But we also create internal batch job services, which like to talk to some facades and services without going through the gateway. For that they do need a JWT, otherwise the batch job will get a 401 not authorized response. Actually, I would prefer those jobs to just go through the gateway. But just as war’s about tabs or spaces, rest or rest-full, Windows or Linux, Eclipse / Netbeans or Intellij, Office365 or Google, you can start arguments on going through a gateway or not 😉 So let’s just make it possible in a simple, safe and standard way…
(4) Cleaner audit-trail logging. At this time, we do mix the audit trail with all other logging of the IDP. Of course you can construct search queries in Kibana to report on just the messages of interest, but I think it would be better to store the audit trail logs in a separate database table. This keeps it nice and clean together, and gives us the option to use a different retention period than the rest of the log messages. Done!
(5) Add the reverse of scope group expanding; scope compression. At this moment, if you do not request a specific scope while creating a token, you will get ALL scopes defined for the client. These are stored in the access and refresh token databases. The number of scopes is getting quite big in our environment, so this takes up quite some data bytes. By changing the IDP to for example just store a “*” if you should get all your client scopes, we could save lots of space. And it solves a second problem; if a client re-uses a refresh token (most of these are valid for 3 months), then the client will get the set of scopes as of creation of the token. But… in the mean time we could have added some services which require new scopes. Even if we add the scopes to the client configuration, the user will not get these, as he/she will get the ones as stored in the refresh token. Having a “*” there, would give the user all scopes again. Our scope groups do already solve this problem partially. These are expanded on each visit. Note: the compression and expansion are not mutually exclusive, they work at the same time: compression in data storage, expansion in JWT generation.
Client Configuration
This is another customization, but it’s outside of the IDP.
For configuring and maintaining Oauth2 client and scope definitions, we (mainly Marc) did build our own GUI web application on top of the IDP database tables. We call this the IDP-UI (user interface). This was build using Vaadin (a framework to quickly create a web application in Java, using standard screen components / layouts). This proved to be a very handy tool by the time we got regular changes in the client and scope configurations. And it made it possible for us to hand administration over to other teams.
The IDP-UI also shows the status of blocked-IP addresses (getting blocked due to too many failed login attempts), and allows you to unblock them manually when needed. IP-blocks do expire after a certain amount of time, but in the past we did have occasions where we accidentally blocked some end-user which did need access again quickly. Think for example of a big corporate proxy, hiding the IP address of many users. If enough of them type in a wrong password, they block the whole proxy. Or we also have had some cases where there was another application between the real end-users and the gateway/IDP, and the initial version of the application forgot to pass on the real client-IP. That also leads quickly to IP-blocks of that complete application. Of course we have created a way for these applications to pass on the real client IP’s in a secure way. But they have to implement their part of that to work properly.
In the client database table, the guys from spring did create a field which contains a free-form, customizable JSON string with “additional information”. We make heavy use of that piece of JSON to store lots of custom flags per client (to configure our customization’s). The IDP-UI nicely presents that JSON field as a key/value pair table. With some data type validations, and where possible drop-down select boxes if the allowed values are limited (for booleans or enumerations). That’s much better than to have to edit a piece of JSON data by hand.
To use the IDP-UI, you need to logon to it (it’s only available on the company intranet). We have connected it to our central tools/developer LDAP system, in which you need to have a certain LDAP group to get access to the IDP-UI. There are currently two groups/roles for this; an editor group, and a view group. The viewers can only look at all settings (apart from the client-secret), and they can un-block blocked IP’s. The editor group is kept as small as possible, and we have an on-boarding form/process to request new IDP client configurations. After multiple approvals send to one of the editor users.
Login Services
We are using the same Gateway/IDP for more than one traffic / authentication flow. We have end-users/customers for multiple retail brand’s, internal employees, and developers. When a client authenticates, he/she needs to provide a user-id and password. These will be checked against a proper back-end, depending on a setting in the client definition.
Customers will be authenticated against their web-site account (using an SQL database with separate accounts per retail brand). Employees will be authenticated using (a corporate) Tivoli Access Manager. And developers will be authenticated against a developer LDAP server (the same LDAP is also used for their Jira/Confluence/Jenkins/Bitbucket/tools accounts).
The login-services are simple spring-boot RESTFull applications, talking to the proper back-end databases. And the Tivoli coupling actually works using a custom (JWT) grant_type (with asymmetric cryptography validation) instead of using a database.
Some Numbers (Performance)
The performance and load we can handle is quite impressive in my opinion. Here some numbers, taken from around end of October 2020, mid-day (the numbers of course change each day):
| Item | Number | Comment |
|---|---|---|
| IDP | 12 instances | The number of containers |
| Gateway | 12 instances | The number of containers |
| Login-Service | 12 instances | The number of containers |
| Postgres | 1 instance | Postgres on a dedicated VM (not in K8S due to on-prem storage requirement – in Azure will be postgres as a service) |
| IDP token create / refresh | 22 ms | Average response time of IDP calls under load. |
| IDP token validity check | 3.2 ms | Response time of call which checks if token is valid. |
| IDP JWT generation | 9.4 ms | Converting access token into JWT (asked by gateway) |
| Postgres | 180 GB | Database size (note: backup file is 33GB, plain text sql, so quite some space in indexes and unclaimed space due to deletes) |
| Access Tokens | 832K | The number of access tokens mid-day but this varies greatly over time. |
| Refresh Tokens | 16.2M | The number of resfresh tokens. This used to be much bigger, but we changed expire from 90 days to 7 days for a big set of tokens. |
| IDP | 3180 req/sec | The number of requests per second coming in to the IDP (production). |
| IDP ACC | 9014 req/sec | The number of performance tested requests per second coming in to the IDP on acceptance environment. We can still grow a bit in PRD 😉 |
| Postgres | 8 cpu’s / 16 GB | Virtual Machine on which Postgres runs |
| IDP | max 2 cpu, average use 0.6 cpu | CPU Resources Per container |
| IDP | max 1.9GB, average 800MB | Memory Resources Per container |
| IDP | 0.9MB | Network traffic Per Container |
| Gateway | max 2 cpu, average use 0.7 cpu | CPU Resources Per container |
| Gateway | max 1.9GB, average 1.6GB | Memory Resources Per container |
| Gateway | 1.9MB | Network traffic Per Container |
| Login-Service | max 2 cpu, avegare use 0.3 cpu | CPU Resources Per container |
| Login-Service | max 1GB, average 450MB | Memory Resources Per container |
| Login-Service | 209KB | Network traffic Per Container |
| Gateway | 2410 req/sec | The number of requests per second coming in to the Gateway (production). |
| Gateway ACC | 5448 req/sec | The number of performance tested requests per second coming in to the Gateway on acceptance environment. |
Of course there are many more numbers / metrics, but this is just an interesting hand full for now to give you an idea of the scale.
Security Consideration
We have learned the hard way, so let’s warn everyone else here 😉 DO NOT USE grant_type=password in any place where a hacker can de-compile your app or find your client_id plus client_secret. If you create a mobile app, you MUST use the full 3-legged Oauth via an embedded web form (with captcha or similar protection on it). Never ever create a native app login screen, which can ask your server via a simple post if the used credentials are correct (e.g. like the password grant type). Having this allows someone to start massively guessing for passwords. We know, app-developers do not like non-native things, but believe me, this is the only simple way to prevent attacks AND maintain super fast flexibility in changing the login procedure without having to roll out a new app version and trying to kill off old versions of the app. Having the web form login allows us to easily add for example 2-factor authentication when we want or need to.
Closing Thoughts
Actually, most closing thoughts are already scattered throughout this post (OK, that does make them non-closing thoughts, or in-between-thoughts)… Let’s collect (and add) some of them:
• Hazelcast; nice stuff but no easy statistics and monitoring available. This makes it hard to monitor, and keep it in the proper scale for running heavy loads. Switching to Postgres or MongoDB is much simpler in scaling and monitoring, so that’s on the plan for some time in the future. Done – We removed Hazelcast from IDP usage…
• Here at the end of writing this post, I think we did lots and lots of useful customization’s. I’m not even sure I remembered all of them. I will have to check the code, the current list was just from memory. And on each blog post review iteration I thought of another customization we did or want to do 😉
• I do realize that my Micro services Architecture blog post series does not contain any source code, or deep technical details. Sorry 😉 But it’s the thought that counts… No, just kidding, it’s the functional idea’s that count. This should give you a deeper insight in the issues we did encounter, and the tweaks we did to fix them.
• Security wise, our Oauth2 IDP is quite good and up to standards. We did have an external review, which agreed on this. Yay! However, I think we can step it up one level, by executing the two mentioned points; improve the audit trail, and block unwanted requests using credentials in query string parameters.
• The number of micro services in our platform grows week by week (as we are migrating from legacy monolith to services). Each of them get new scopes assigned for access-control. This leads to an explosion of scopes needed on access and refresh tokens. As mentioned earlier this leads to two problems. First one: overuse on disk space storage (not kidding, we even had to make the scope column much wider, and we have many many tokens). And second one: If a user has an active refresh token, and we add new scopes to the client, then the user will not automatically get those new scopes. This needs a fix (as described earlier).
• I’m quite proud of what we created, and keep running for so long with success. The IDP and Gateway became very important parts of our platform, websites, and mobile app’s. I’d like to split the credits between my former colleague Marc Kamerbeek and me, as main contributors of the adoption of these components and it’s customizations. Thanks Marc!
That’s it for part 3 of the series.
Thijs.
All parts of this series:
- Part 1 – Overview
- Part 2 – Gateway
- Part 3 – IDP
- Part 4 – Oauth2/Scopes
- Part 5 – From Legacy Monolith to Services
- Part 6 – Oauth2 and Web
2 thoughts on “Micro-services Architecture with Oauth2 and JWT – Part 3 – IDP”
Great article & practical ideas!
But when will part 4/5 come out? I am just waiting …
Thanks! Yes, sorry 😉 I really need to finish the series sometime soon.