Micro-services Architecture with Oauth2 and JWT – Part 1 – Overview
The last number of years I have been working in the area of migrating from legacy monolith (web) applications to a (micro) service oriented architecture (in my role of Java / DevOps / Infrastructure engineer). As this is too big of a subject to put in a single blog post, I will split this in 6 parts; (1) Overview, (2) Gateway, (3) Identity Provider, (4) Oauth2/Scopes, (5) Migrating from Legacy, (6) Oauth2 and Web.
Introduction
For migrating from legacy monolith (web) applications to something more modern and manageable, we have been switching to micro-services.
We are using an API Gateway for routing to the proper service, and the Gateway checks authorization with our (Oauth2) Identity Provider (IDP). When traffic passes through the Gateway, it exchanges the Oauth2 token for a more usable JWT (Json Web Token).
The size of this setup is quite serious, as I am working for a big retailer. “We” have over 900 brick-and-mortar/non-virtual stores with Point of Sale (POS) machines talking to our platform. There are a number of distribution centers talking to our platform (for order picking). There are lots of delivery drivers communicating with an app via our gateways also. And of course our biggest source of traffic; a number of e-commerce websites for on-line sales and on-line marketing (bonus offers, product information, news articles, etc).
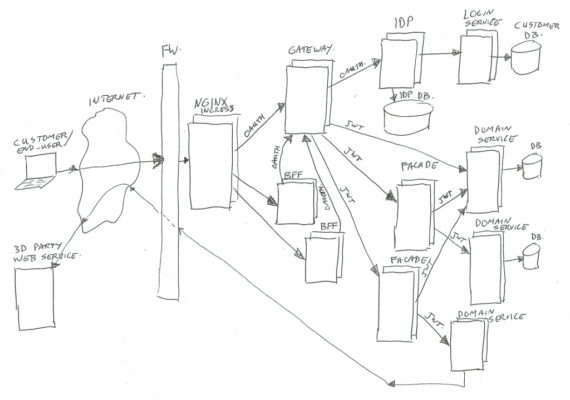
The simplified architecture image looks like this (click to zoom):
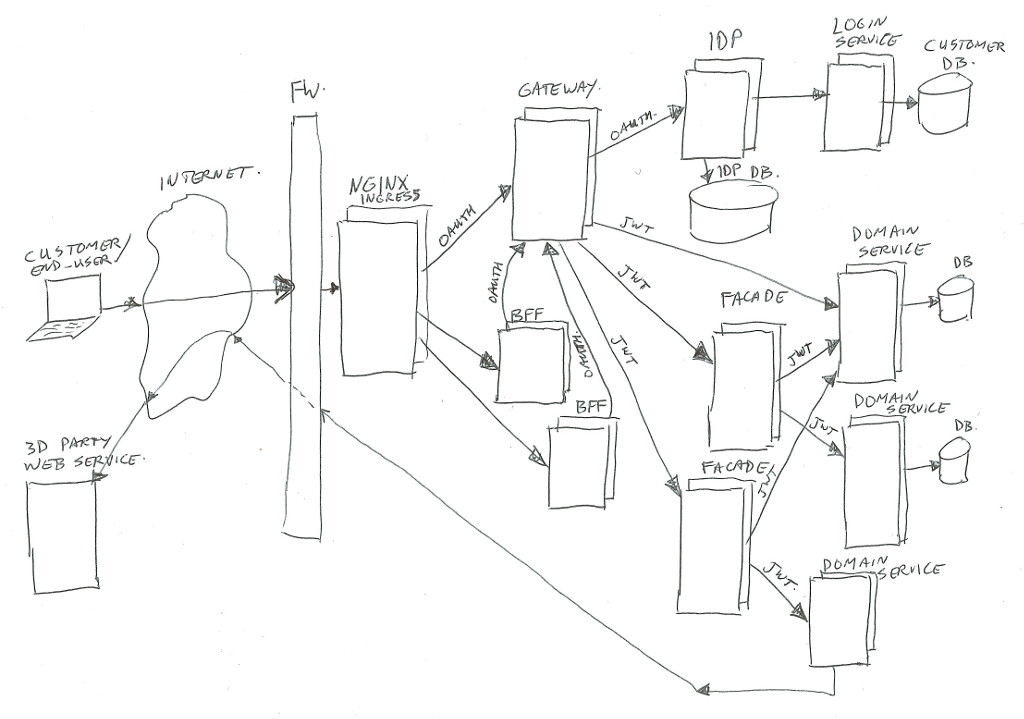
In real life there is much more around the image than has been shown… for example infrastructure components for security (intrusion detection/prevention, DDOS prevention, WAF / Web Application Firewall), load-balancing, virtual hosting, Kubernetes components, virtual networks, logging frameworks, monitoring frameworks, databases, legacy applications, proxy-servers, and much more.
As our services/platform team consists of Java developers, we chose for Java (or Kotlin) implementations for most of the custom build components. Of course we also have lots of front-enders, and they use Node.js (see BFF section).
The Parts
A description going from left to right of all parts;
User
The user… could be an actual person behind a web browser on his/her laptop or mobile phone, talking to our BFF’s.
Or it could be an application (mobile app, or third-party server) talking to our Gateway to get to our domain services.
Internet
Right… I’m assuming you sort of know what the Internet is (or at least in high level). For this example just the data connection between the user and us.
Nginx
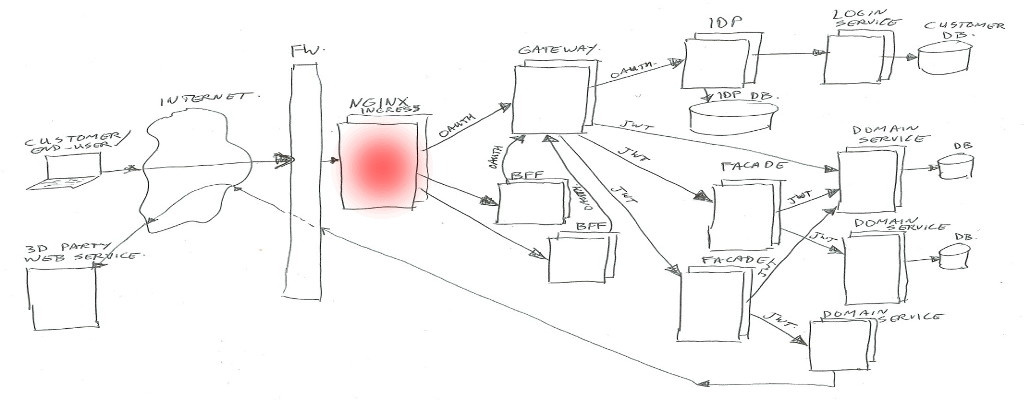
We are using Kubernetes (In short K8S), which is a container orchestration system. It is managing applications on many Linux hosts, using docker containers.
Kubernetes is leaning on Nginx as glue between traffic from the outside to internal functions. Nginx is the HTTP server used to route/proxy traffic to for example the BFF’s or directly to the Gateway.
Note: Kubernetes does call that Nginx “Ingress”, as it does consist of Nginx plus a program (Ingress Controller) to manage which vhost/path mappings to serve (using Ingress Rules).
BFF
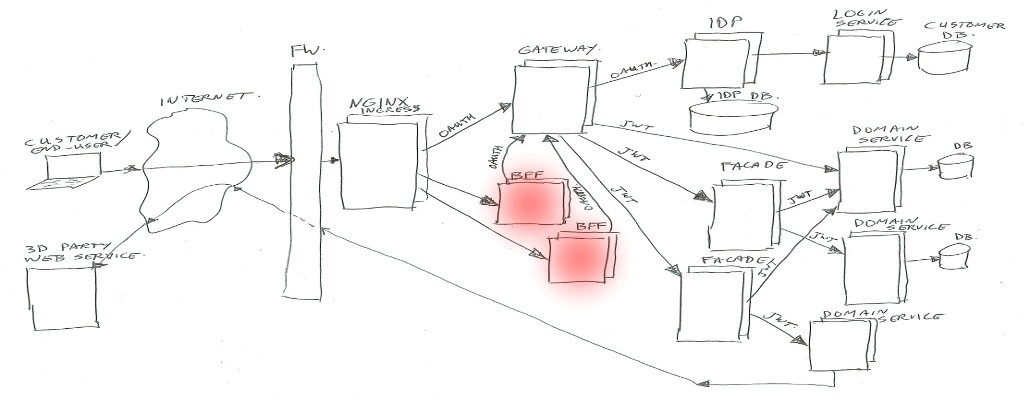
BFF is backend-for-frontend (so it’s not best-friends-forever in this context – of course you are aware of the ongoing cold war between frontend and backend – no, just kidding 😉 ).
This BFF is for example a small Node.js web application serving html/css/js, and handling ajax json data calls. Or in some cases it could be just a machine-2-machine rest/json/data interface for transforming and combining service data.
In both cases, the BFF will handle the external (frontend) traffic, and make it suitable to talk to our backend services via the Gateway.
The authentication/authorization is left to the Gateway and IDP.
For the web application use-case, our frontend developers tend to use Node.js. For the machine-2-machine BFF’s we are using Java or Kotlin spring-boot applications.
Gateway
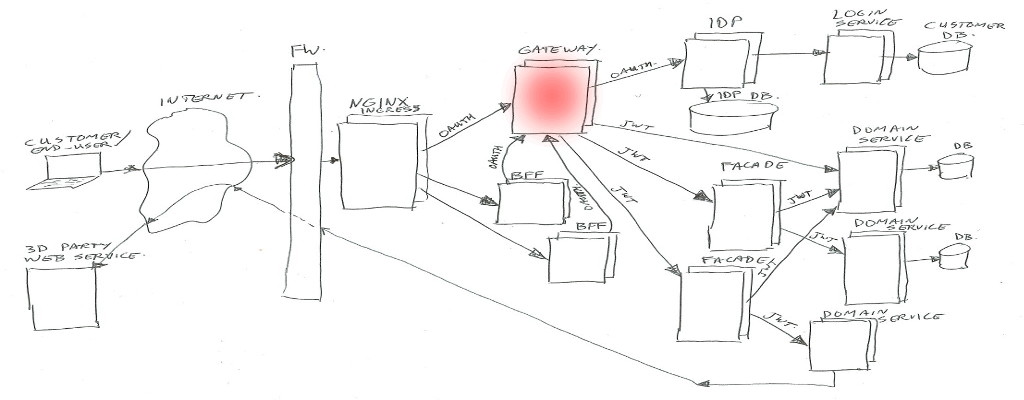
In summary the Gateway handles routing of calls to the proper destinations (service / facades / IDP), and enforces the security check’s.
And next to exchanging Oauth2 tokens to JWT’s it has quite some extra things to look after.
The Gateway gets its own article/post (Part 2), to describe all the extra’s.
Identity Provider (IDP)
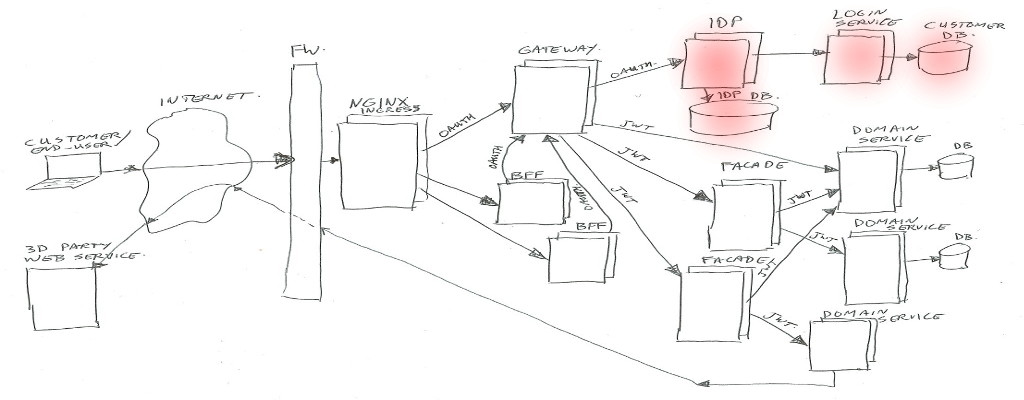
Also the Identity Provider (IDP) will get its own article/post.
In summary the IDP is the component which handles the Oauth2 protocols, checks user credentials, manages Oauth2 tokens, and creates JWT’s for use by our services. It uses the login-service to authenticate users.
Facade
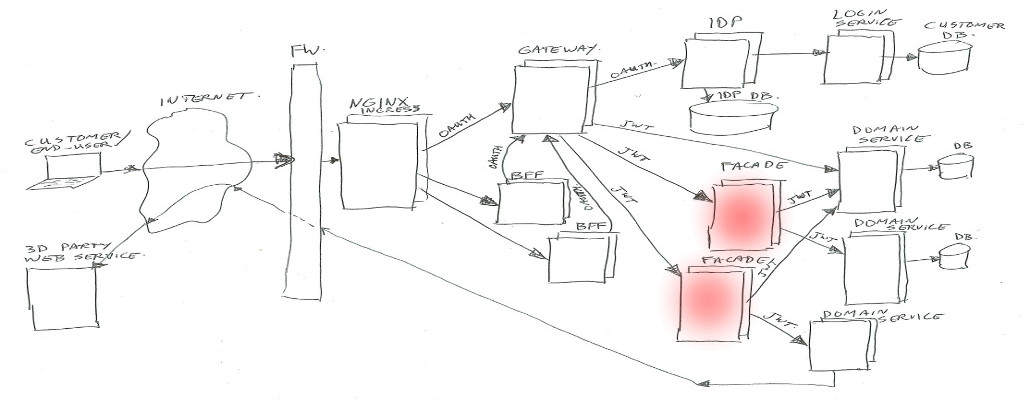
Facades actually come in multiple flavors. Their purpose is to combine different domain-services into one view / one endpoint, transform data structures, enrich data, and sometimes handle some business logic.
Facades are allowed to have their own data-storage if needed, and they may call multiple domain-services, or in some special cases may call another facade (but preferably not, to prevent spaghetti dependency calls).
If a facade needs to know anything about the client or customer or Oauth2 scopes, it can look in the passed in JWT header value. The JWT contents will be trusted if signed by our IDP.
Facades are mainly build as Java/Kotlin spring-boot applications.
Domain Services
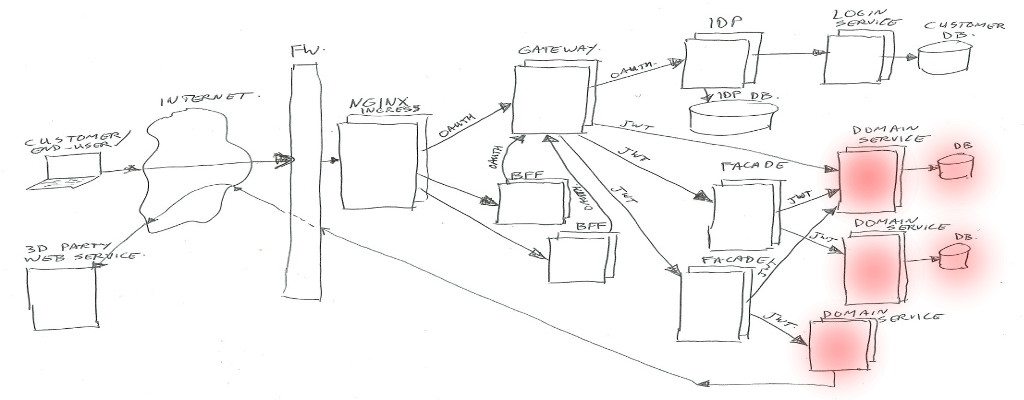
Domain services are the bottom layer (furthest away from the customer) in our Kubernetes cluster.
These services contain business logic, can have their own databases, or can call external/remote service API’s where needed. They are NOT allowed to call other domain services or facades in our cluster. This is to keep a clear separation of concern, and to prevent multiple domain-services to be depending on each other.
We also want this separation both to keep the code clear and maintainable. And to prevent teams from having to change more than one domain-service at a time, and to stay out of each others way where possible. There’s nothing more annoying than two teams having to modify the same piece of code at the same time 😉
Example services; order-service, customer-service, shopping-list-service, recipe-service, etc…
Just like facades, if a service needs to know anything about the client or customer or Oauth2 scopes, it can look in the passed in JWT header. It will be trusted if signed by our IDP.
In a micro-service architecture, the services (and facades) are stateless. To scale for heavy loads, you can run multiple copies/instances of the same service. It does not matter in which instance your request will be handled, and a next request can end up in a different instance.
If you need to do caching, you might end up with multiple copies of the same cache data due to having multiple instances. Or… you can use a distributed cache or a database. The choices depend on the amount of data, volume of traffic, and the need for speed. We use local instance memory caches, distributed Hazelcast clusters, Postgres databases, Mongo databases, and some more solutions (Ignite, Redis, …).
Due to this statelessness, the services do not know about a user session. They only get to know which user is talking via the JWT data. Any state or session must be stored at the users end (in the web browser or mobile app), or at the server side in a database.
Http Request Tokens
Each request done in the shown architecture image will have some sort of token attached (using an HTTP request header), for use in authentication (who are you) and authorization (what is allowed).
There are two types in use; between user/client and gateway we use Oauth2, and between gateway and services we use JWT.
Oauth2 Tokens
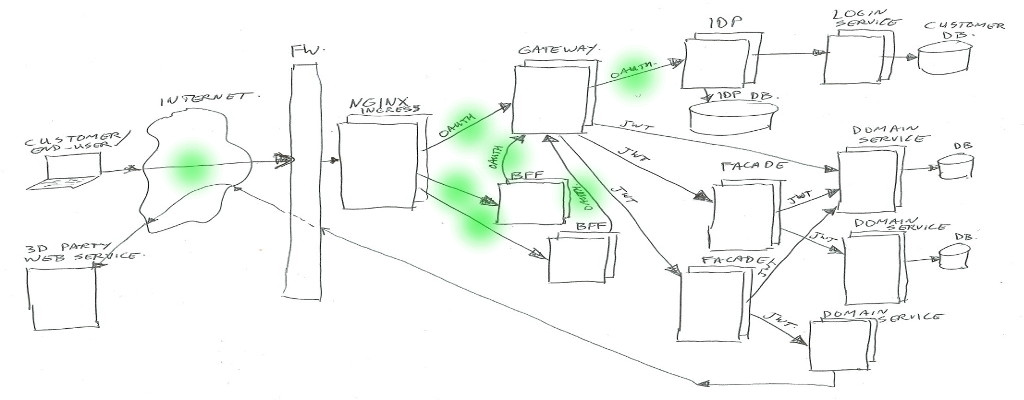
Oauth2 is a standardized authorization framework. This uses so called “access tokens” to identify user/client requests (both authentication and authorization), and uses “refresh tokens” to renew expired access tokens.
To be able to execute service calls, you will first have to ask the Identity Provider for an access (and optional refresh) token. There are different ways to ask for these, to be used for different use cases.
The access and refresh token values do not carry any information, they are just random generated (unique) ID’s. These ID’s are stored in the IDP database, and connected to these ID’s there is authentication and authorization data in the database.
Part 4 of this blog series will cover Oauth2 in more detail.
Json Web Tokens (JWT)
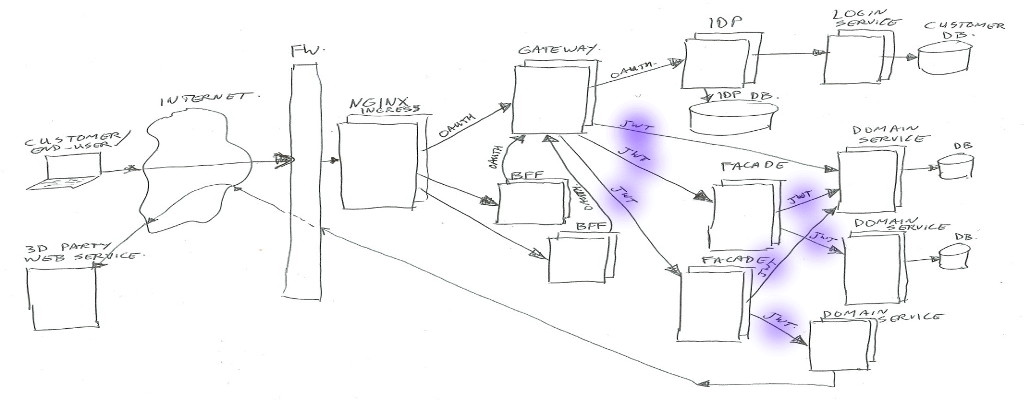
The Json Web Token (or in short JWT) contains information about the authenticated user, and the active Oauth2 scopes (authorizations).
For the user we put the customer number(s), name / address data, and some flags and shop/usage context in there.
The data is in Json format, but when passing it around, it is base64 encoded and signed. Receivers must check the signature before trusting the contents.
The scopes are used to indicate access rights to service end points / data.
The JWT is not send back to the end-user in our case (because it contains sensitive/personal data). If you would want to send it to a customer, it should be encrypted instead of just encoded.
A common made mistake in the teams; calling it a “JWT Token”… No, no, no… it’s a “JWT”, “JW-Token”, “JWT Object”, “JWT Data”, etc… not a “Json Web Token Token” 😉
Closing thoughts
We are giving Oauth2 access and refresh tokens to the end-users (as web cookies, or in mobile app storage).
However, in our architecture we do have different levels of authentication/authorization for visitors; (1) anonymous user, (2) returning non-registered users, (3) returning registered not logged in users, (4) logged in (registered) users. And more (in between) levels might be coming up for some special use-cases…
Without going into detail, I can let you know that this is quite complex matter, for which lots of (library) logic is needed in all BFF’s to find the exact case/state. With each of these levels we have cases where tokens expire and need refreshing, with or without falling back to different lower levels depending on outcomes. It is becoming sort of a small nightmare.
It makes me wonder if going full Oauth2 on the web end-user is a good choice, or at least not like this.
Perhaps a construction in which the end-user just gets a single session (Oauth2) token, and having a session manager and session storage as entry point/proxy in front of the web BFF’s would be a better solution.
The session manager can hold the session state, manage state changes, and manage all cached session attributes. It can pass them on to the BFF’s and services as request header values.
I think that would simplify the architecture for web use quite a lot… But perhaps that’s a nice subject for a different post 😉 → Added it in post part 6.
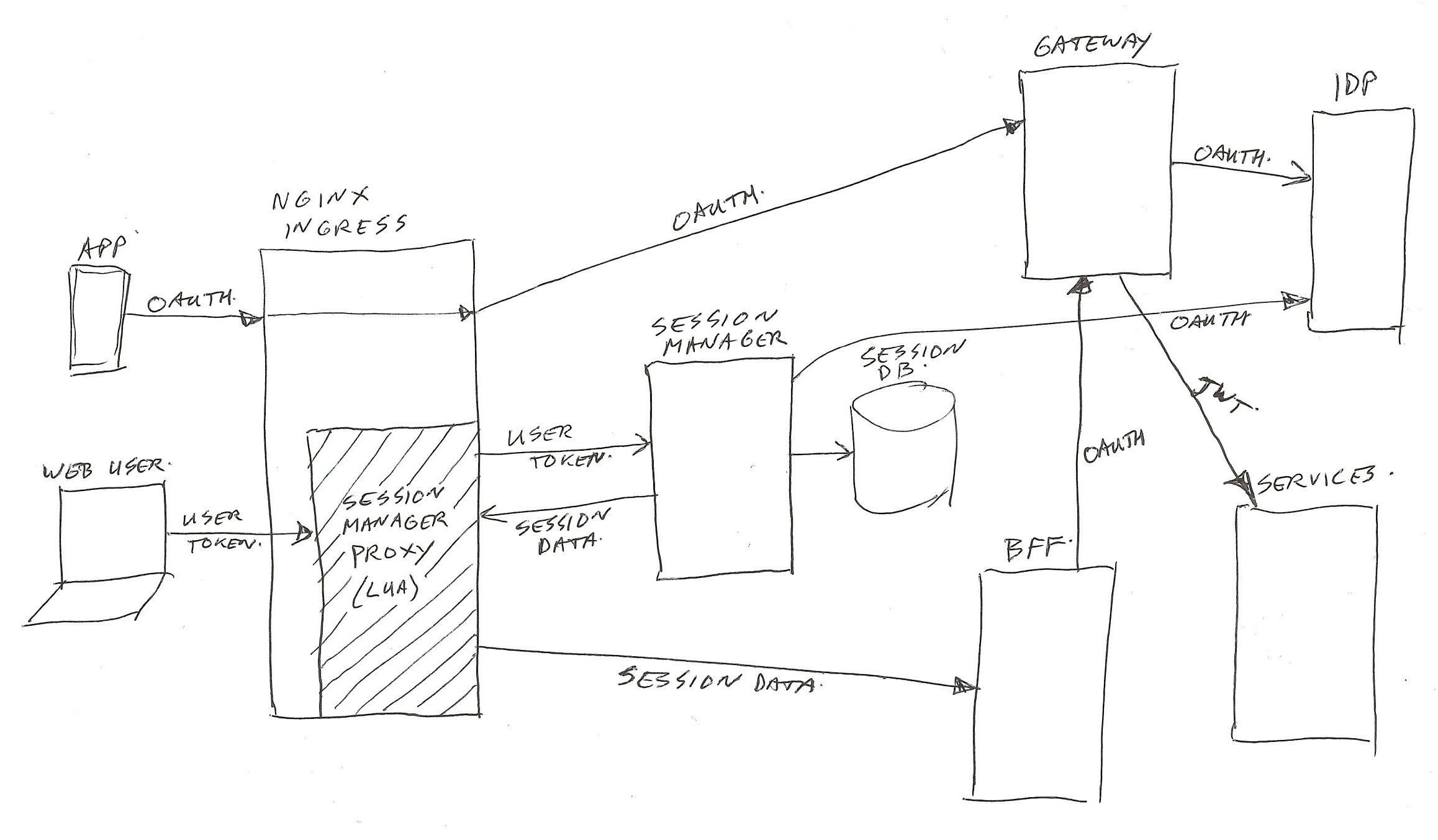
For use by mobile app’s, and external systems, the current Oauth2 gateway service architecture works quite well. And apart from the visitor level complexity, it functions fine for web use also.
Also running all of this (not the monolith’s) in an on-premise Kubernetes cloud works quite well! Very well saleable, fast / simple Continuous Integration (build+test) / Continuous Deployment (CI/CD); just pressing a single Jenkins or pull-request button. Nice!
That’s it for part 1 of the series.
Thijs.
All parts of this series:
- Part 1 – Overview
- Part 2 – Gateway
- Part 3 – IDP
- Part 4 – Oauth2/Scopes
- Part 5 – From Legacy Monolith to Services
- Part 6 – Oauth2 and Web
Terminology
This section is for service beginners – skip this for advanced IT-ers…
Micro Service
A Micro Service is a small program having limited responsibilities around a single subject, using a clean / simple interface to talk to it.
For building an application, you need to use many of these together.
Advantage; small, simple, quick to compile/build, and each team can work most of the time on their own services.
Disadvantage; takes careful work to keep it working for all end users, also after changing the interface (so keep old versions working also). And it takes a bit more communication overhead to call all the needed services. Easy to loose track of which components are calling upon your service (so difficult to find who to contact when deprecating interfaces).
Best practice for a micro service is to have it’s own (not shared) databases / storage. This to prevent unwanted communication / side-effects of others reading / updating the database directly without consulting the service. Having it’s own data also allows for easy changing of the type or structure of storage, while keeping the service interface unchanged.
Legacy Monolith
A Legacy Monolith is a big (old) program having many responsibilities around all subjects needed for the application user, using complex internals.
Advantage; simple deploy, everything fits together with proper versions of all internal parts. And no external communication to reach the different internal parts.
Disadvantage; it’s one big build, which is not handy if you need to work on it with many teams at the same time. Takes long to compile/build.
Internet
If you need more info on the Internet, you can look it up here:
https://www.youtube.com/results?search_query=it+crowd+internet+in+a+box 😉
3 thoughts on “Micro-services Architecture with Oauth2 and JWT – Part 1 – Overview”
Hello,
Thanks for writing this series of articles , it’s very helpful. But I have a question:
usually bff is running behind Api gateway and doing api composition for frontend.
In your diagram, you put bff layer in front of gateway and you create extra facade service for api composition. Is that really necessary?
Is your facade service act as bff?
Thanks.
Hi, thanks for your feedback and question. On our project, somehow the term BFF got used in the wrong way, so we have “real” BFF’s behind our gateway where they should be (yes, we also call them facades, but some teams call them BFF), but we also have things which were called BFF by some which are in front of the gateway. This has made our life quite confusing 😉 The BFF’s in front of the gateway are actually more like web-app’s, or in some cases special interfaces to pick up non-oauth2 requests and pass them on using oauth2. For example we run some payment confirmation web-hook modules where the bank does not send oauth (but our services do require that). And we have some mobile-app’s which start off without oauth2 for some requests, and later switch to oauth2. Sometimes we call them BFF also, and sometimes we call them proxies. Whenever confusion arises, I tend to just draw a quick image to get everyone on the same line again.
Thank you so much for answering my question!